Теория инвестиций для начинающих, часть 1
 Эдвард Мэтью Ворд. Пузырь Компании Южных морей. 1847 г. Галерея Тейт, Лондон.
Эдвард Мэтью Ворд. Пузырь Компании Южных морей. 1847 г. Галерея Тейт, Лондон.
В какие ценные бумаги вкладывать деньги? Как накопить на пенсию? Кто такие ETF’ы и почему все с ними носятся? Зачем покупать акции, если рынок может упасть? Такие вопросы я слышу от студентов и коллег, когда читаю лекции о деривативах. В принципе, неудивительно. Деривативы — это что-то далёкое из мира больших банков, а личные инвестиции намного ближе к телу.
Можно было бы ответить коротко: «Покупайте индексные фонды, это хорошо!» К сожалению, такой ответ не объясняет, почему это хорошо. Если бы я услышал его 15 лет назад, когда ещё не интересовался финансами, то он не нашёл бы отклика в моём сердце. Пришлось прослушать не один курс лекций, чтобы осознать, какая экономическая теория стоит за этим советом, и начать применять его на практике.
Собственно, моя статья — не столько инвестиционный совет (хотя я и расскажу о личном опыте и даже посчитаю свою «альфу»), сколько обзорный курс по теории инвестиций. Полезно знать, какие модели придумали предыдущие поколения, и в каких терминах можно думать об инвестициях. Если из теории следует, что имеет смысл покупать индексные ETF’ы, чтобы копить на пенсию — так и быть, расскажу и об этом.
Не секрет, что в финансах много математики. Я постарался соблюсти баланс. Я считаю, что интуитивное понимание главных экономических идей важнее, чем конкретная формула. Даже если вы пропустите вообще все формулы, то вы всё равно поймёте суть и получите полезные знания. С другой стороны, если вы хотели бы размять мозги не ахти какой сложной математикой, то у вас будет такая возможность.
Рациональные инвесторы и избегание риска
Чтобы строить теорию инвестиций, нужно договориться о некоторых свойствах инвесторов, которые населяют наш уютный теоретический мирок. Как и большинство инвесторов в реальном мире, наши сферические инвесторы будут любить доходность и не любить ненужный риск. Из двух инвестиций с одинаковой доходностью они выберут ту, что несёт меньший риск. Из двух инвестиций с одинаковым риском они выберут ту, что обещает более высокую доходность.
Кому-то может показаться, что избегание риска (risk aversion) — это нерациональное поведение слабых духом homo sapiens. На деле же рациональный до мозга костей homo economicus тоже будет избегать ненужного риска, если мы сделаем несколько предположений о том, как он принимает решения [BKM14, ch. 6.1].
Предположим, что рациональный инвестор максимизирует функцию полезности (utility function). Это означает, что все-все-все альтернативы, которые он рассматривает, подаются на вход некоторой функции u(x), которая присваивает каждой альтернативе число — полезность (utility). Из множества доступных альтернатив рациональный индивид всегда выбирает ту, которая даёт наибольшую ожидаемую полезность.
Допустим, что функция полезности рационального инвестора — десятичный логарифм количества долларов на счету. Каждый новый доллар на счету увеличивает полезность (уровень счастья), потому что логарифм — возрастающая функция. Кроме того, каждый следующий доллар приносит меньше счастья, чем предыдущий, потому что логарифм — выпуклая вверх (concave) функция. Никакие другие параметры помимо суммы на счету нашего инвестора не интересуют.
Такая форма функции полезности неплохо описывает реальное поведение людей. Согласитесь, что пятый подряд шоколадный пончик с шоколадной начинкой и шоколадной крошкой приносит меньше удовольствия, чем первый. Точно так же пятый миллиард приносит меньше радости, чем первый.
Итак, рассмотрим инвестора с логарифмической полезностью. Сейчас у него на счету $100 000, которые дают полезность lg 100 000 = 5.0 условных единиц счастья.
Посмотрите на таблицу 1.1. Инвестор должен вложить всё своё состояние в один из двух инструментов: либо в абсолютно надёжные облигации, либо в рискованные акции. Что бы ни произошло в будущем, облигации совершенно точно вырастут на $5 000, и инвестор через год будет иметь $105 000. Акции либо с вероятностью 50% вырастут на $25 000 и будут стоить $125 000, либо с вероятностью 50% упадут на $15 000 и будут стоить $85 000. Математическое ожидание вложения в акции равно 0.5 ⋅ $85 000 + 0.5 ⋅ $125 000 = $105 000, то есть совпадает с тем, что обещают безрисковые облигации.

Таблица 1.1: Капитал и полезность инвестора в случае инвестиций в облигации или в акции.
Давайте теперь посчитаем полезность. В результате вложения в облигации инвестор получит полезность lg 105 000 = 5.021 условных единиц счастья. Если он вложится в акции, то с вероятностью 50% акции вырастут, и полезность составит lg 125 000 = 5.097. Однако с вероятностью 50% акции упадут, и полезность будет равна lg 85 000 = 4.929. Средняя ожидаемая полезность от инвестиции в акции, таким образом, равна 0.5 ⋅ 5.097 + 0.5 ⋅ 4.929 = 5.013.
Из-за формы функции полезности радость от добавочных $20 000 по сравнению с облигациями в хорошем сценарии (5.097 − 5.021 = 0.076) по модулю меньше, чем расстройство от упущенных $20 000 в плохом сценарии (4.929 − 5.021 = −0.092). Потерянные с вероятностью 50% $20 000 ценнее, чем заработанные с вероятностью 50% $20 000.
Так какую же из двух альтернатив выберет наш рациональный инвестор: облигации с ожидаемой полезностью 5.021 или акции с ожидаемой полезностью 5.013? Ответ очевиден: 5.021 больше, чем 5.013, поэтому инвестор выберет облигации. При одинаковой ожидаемой доходности (в обоих случаях ожидаемый капитал составляет $105 000) рациональный инвестор выберет менее рискованную альтернативу, то есть проявит то же самое избегание риска, что и реальные биологические инвесторы.
Как изменить условие задачи, чтобы инвестор хотя бы воспринимал две альтернативы безразлично? Можно, например, пообещать ему более высокую доходность акций в хорошем случае. Если акции будут приносить не $125 000, а $129 706, то, как показано в таблице 1.2, ожидаемые полезности двух альтернатив совпадут.

Таблица 1.2: Капитал и полезность инвестора в случае инвестиций в облигации или в акции. Акции имеют более высокую доходность по сравнению с таблицей 1.1.
Чтобы уравнять ожидаемые полезности, нам пришлось улучшить математическое ожидание дохода от акций. Раньше акции давали в среднем $105 000, а теперь $107 353, на $2 353 больше. Эти $2 353 дополнительной ожидаемой доходности — премия за риск (risk premium), которую требует инвестор, чтобы рассмотреть возможность покупки акций. Премия за риск уравнивает прибавку полезности в хорошем случае (5.113 − 5.021 = 0.092) и снижение полезности в плохом случае (5.021 − 4.929 = −0.092). Если накинуть к доходности акций ещё доллар, то инвестор предпочтёт их облигациям.
Эти рассуждения верны не только для инвесторов с логарифмической полезностью. Достаточно, чтобы функция полезности была возрастающей и выпуклой вверх. Тогда инвесторы будут избегать риска и требовать премию (добавочную доходность) от рискованных инвестиций. Запомним эту мысль. Она пригодится, когда мы будем говорить о теории CAPM.
Корреляция с рынком
Рассмотрим ещё один модельный пример, основанный на идее из лекции профессора Джона Кохрэйна (John Cochrane) [Coc13].
Есть две акции, A и B, каждая из которых может принести в будущем либо $1 000, либо $500 с вероятностью 50/50. Акции устроены так, что когда акция A приносит $1 000, акция B приносит $500. И наоборот, когда A приносит $500, B приносит $1 000. Математическое ожидание дохода от каждой акции равно $750. При прочих равных, какой акцией вы хотели бы владеть? Забудем о цене и предположим, что акцию вы получите в подарок.
На первый взгляд, акции совершенно симметричны. Нет никаких рациональных аргументов, чтобы предпочесть одну акцию другой. Вы могли бы подбросить монетку, положиться на случай и не прогадать. Верно? Не совсем. Что, если я уточню, в каких именно сценариях акция A приносит $1 000, а в каких $500?
Предположим, что в будущем возможны два сценария. С вероятностью 50% вы потеряете работу или другой источник дохода, и в этом же сценарии акция A будет стоить $1 000, а акция B будет стоить $500. С вероятностью 50% вы не только не потеряете работу, а даже получите премию $10 000, и в этом же сценарии акция A будет стоить $500, а акция B будет стоить $1 000. Эти альтернативы перечислены в таблице 1.3.

Таблица 1.3: Две акции дают одинаковый ожидаемый доход, но приносят большую пользу в разных состояниях мира.
Когда на лекции я провожу голосование среди студентов (живых людей, а не рациональных роботов), все в один голос заявляют, что предпочли бы владеть акцией A. Это соответствует простой житейской мудрости. Акция A принесёт дополнительные деньги именно в «плохом» сценарии, когда каждый доллар на счету. Акция A похожа на страховку от потери работы, и поэтому люди её ценят.
Примечательно, что рациональные логарифмические инвесторы из нашей теории будут вести себя точно так же. Поскольку функция полезности выпукла вверх, они будут больше ценить акцию A. Акция A приносит больший доход в «плохом» сценарии, когда каждый дополнительный доллар более ценен. С другой стороны, акция B приносит $1 000 в «хорошем» сценарии, когда у инвестора и так прибавится $10 000, и добавочная полезность от $1 000 будет не столь велика.
Сделаем следующий шаг. Предположим, что в нашей экономике не один рациональный инвестор, а множество. Каждый из них предпочтёт ту акцию, которая защитит его от потери работы. Что, если риск потери работы одним инвестором связан (скоррелирован) с потерей работы остальными? Это вполне разумное предположение. Согласитесь, что для большинства людей шансы потерять работу в кризис выше, чем в хорошие времена. Кризис потому и кризис, что плохо становится сразу многим компаниям, и многие люди теряют работу одновременно.
Получается, что больше инвесторов хотят владеть «защитной» акцией A. Если инвесторы покупают и продают акции на свободном рынке, то спрос на акцию A будет выше, чем спрос на акцию B. При прочих равных, в равновесии акция A будет стоить дороже, чем акция B.
Что это означает для доходности инвестиций в акцию A и акцию B? Для начала давайте договоримся о формальном определении, что такое доходность. Допустим, что вы купили актив (акцию, облигацию, квартиру) в момент времени t по цене Pt, а в момент времени t+1 актив стал стоить Pt+1. Кроме того, вы получили от актива денежную выплату (дивиденды, купон, арендную плату) Dt+1. Тогда ваша полная доходность за период времени между t и t+1 составила
Например, предположим, что инвестор купил акцию B за Pt = $600. Реализовался «хороший» сценарий, и акция стала стоить Pt+1 = $1 000 и не заплатила никаких дивидендов (Dt+1 = $0). Тогда инвестор заработал $1 000 ∕ $600 − 1 ≈ 66.7%.
Если считать, что будущая цена Pt+1 и будущие дивиденды Dt+1 — случайные величины, то будущая доходность Rt+1 — тоже случайная величина. Поэтому формулу (1.1) можно записать и для математических ожиданий:
Выглядит как урок арифметики для старшей группы детского садика, но он показывает нам важную деталь. Текущая цена Pt стоит в формулах (1.1) и (1.2) в знаменателе, поэтому при той же будущей цене и будущих дивидендах более низкая цена сегодня означает большую ожидаемую доходность в будущем.
Как мы выяснили, инвесторы будут предпочитать акцию A акции B. Если инвесторы не получают акции в подарок, а покупают их на рынке, то спрос на акцию A окажется выше, чем на акцию B. Следовательно, в равновесии цена акции B должна быть ниже, а ожидаемая доходность — выше! Например, если рынок оценит акцию A в $700, а акцию B в $650, то по формуле (1.2) ожидаемая доходность акции A составит $750 ∕ $700 − 1 ≈ 7.1%, а акции B — $750 ∕ $650 − 1 ≈ 15.3%.
Таким образом, инвесторы будут зарабатывать более высокую доходность (большую премию за риск) на активах, похожих на акцию B. Это те активы, которые сильнее связаны с общим состоянием экономики, то есть растут в хорошие времена и падают в плохие. Поставим крестик, чтобы вернуться к этой идее позже, когда будем изучать CAPM.
Вспоминаем теорию вероятностей
Чтобы продолжать строить теорию, нам нужно воспользоваться несколькими тривиальными фактами из теории вероятностей. Вы можете смело пропустить этот раздел, если вам не составляет труда прочитать и понять следующую фразу: «Дисперсия суммы равна сумме дисперсий плюс две ковариации».
Я предполагаю, что все более-менее интуитивно понимают, что такое математическое ожидание случайной величины. Для наших целей совершенно нет необходимости знать, что это интеграл Лебега. Достаточно простой интуиции, что мат. ожидание — это среднее значение случайной величины. Я буду обозначать мат. ожидание случайной величины X как E(x).
Например, если мы бросаем игральный кубик, то выпавшее количество очков — это случайная величина X, которая имеет мат. ожидание
Важное свойство мат. ожидания — линейность. Например, если я бросаю не один кубик, а четыре, и складываю выпавшие очки, то мат. ожидание суммы будет равно 4 ⋅ 3.5 = 14. Формально это можно записать так (α и β — константы, X и Y — случайные величины):
Дисперсия случайной величины показывает, насколько велик разброс значений вокруг среднего. Чем больше разброс (например, чем дальше друг от друга минимум и максимум), тем больше дисперсия. Стандартное отклонение — это квадратный корень из дисперсии. Я буду обозначать дисперсию случайной величины X как Var(X), а её стандартное отклонение как σX.
В примере с игральным кубиком дисперсия будет равна
Предположим, что у нас есть две случайные величины X и Y. Резонно задать вопрос: а есть ли связь между X и Y? Например, верно ли, что большие значения X чаще выпадают одновременно с большими значениями Y? Ответ на этот вопрос дают ковариация, которую я буду обозначать Cov(X,Y), и коэффициент корреляции, который я обозначу ρX,Y.
Чтобы визуализировать идею корреляции, я четыре раза попросил компьютер сгенерировать по 250 случайных реализаций стандартных нормальных величин X и Y. Четыре эксперимента отличаются только корреляциями между X и Y. Результаты представлены на рисунке 1.1. Как видите, чем ближе корреляция к 1, тем очевиднее линейная связь между X и Y.
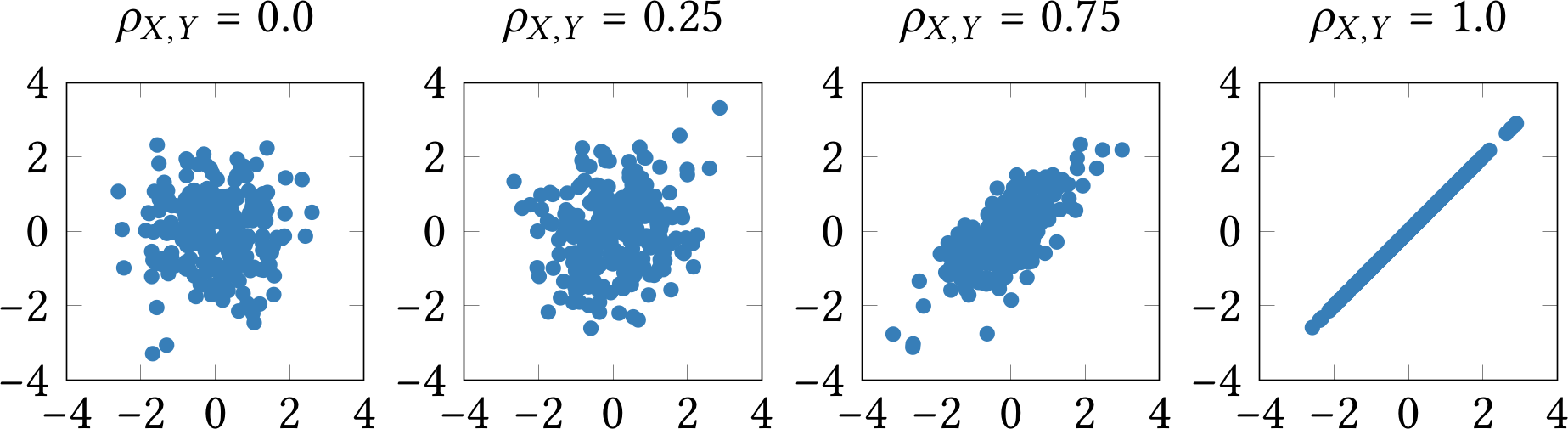
Рис. 1.1: Реализации случайных величин X и Y в зависимости от корреляции между ними.
Нам понадобится правило для вычисления дисперсии суммы случайных величин. Дисперсия суммы зависит как от дисперсии слагаемых, так и от ковариации (или от корреляции) между ними:
Диверсификация, или о пользе корреляций
Если бы я мог дать вам всего один совет касательно инвестиций, то я бы сказал: «Диверсифицируйтесь!» Или, следуя народной мудрости, не кладите все яйца в одну корзину.
Есть несколько довольно популярных заблуждений по поводу диверсификации. Первое — что диверсификация уменьшает доходность. Второе — что диверсификация возможна, только если активы, в которые вы инвестируете, связаны отрицательной корреляцией. Это не так, и если вы, как и остальные инвесторы, не любите риск и любите доходность, то вы можете улучшить баланс риска и доходности с помощью диверсификации.
Рассмотрим пример. Пусть у нас есть всего две акции, X и Y. Мы знаем, что они имеют одинаковую ожидаемую доходность μ = 5% и одинаковое стандартное отклонение σ = 10%. Кроме того, они связаны друг с другом корреляцией ρX,Y = 0.4. Вы должны вложить долю w своего капитала в акции X, а долю (1 − w) — в акции Y.
Зависит ли ожидаемая доходность ваших инвестиций от выбора w? Нет, не зависит. Из линейности мат. ожидания следует, что при любом выборе w вы всегда получите одну и ту же ожидаемую доходность 5%:
А что с риском? Из формулы (1.3) следует, что дисперсия и стандартное отклонение зависят не только от стандартного отклонения каждой акции, но и от корреляции между ними:
Невооружённым глазом видно, что дисперсия портфеля (то есть риск) есть квадратичная функция от w. Стало быть, при каком-то w она должна достигать минимума. Как показано на рисунке 1.2, этот минимум действительно достигается при w = 0.5, то есть если вы инвестируете половину капитала в акции X и половину в акции Y. Стандартное отклонение доходности вашего портфеля составит 8.37%. С другой стороны, если бы вы инвестировали все деньги только в акцию X (или наоборот, только в акцию Y), то вам бы пришлось смириться со стандартным отклонением целых 10%.
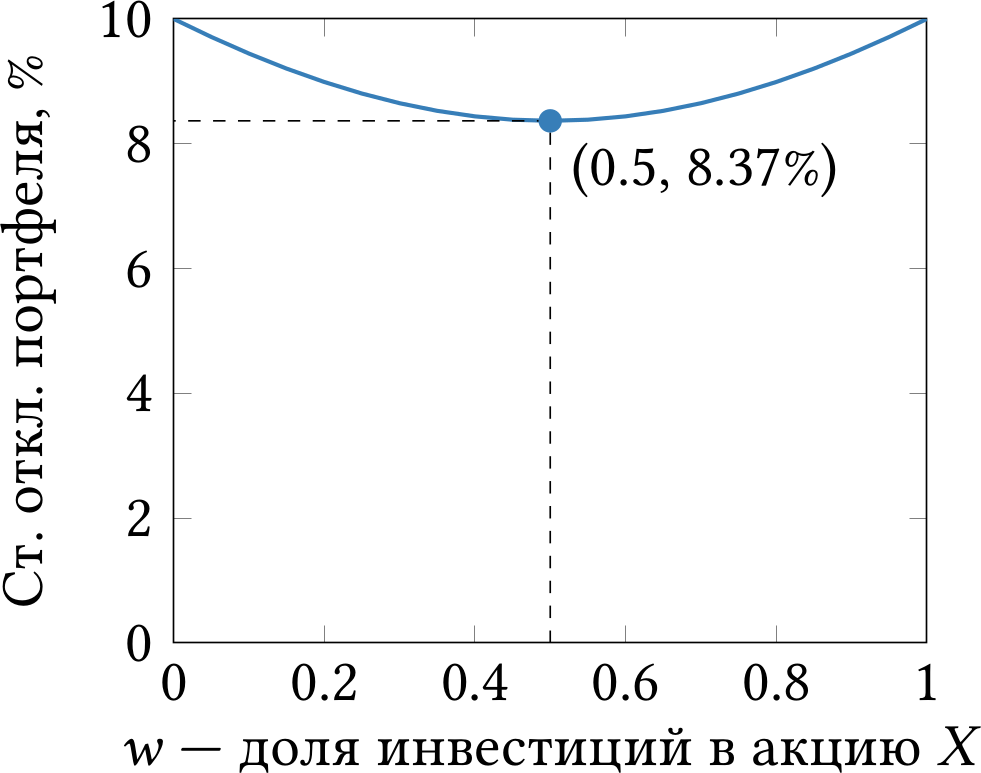
Рис. 1.2: Зависимость стандартного отклонения доходности портфеля от доли инвестиций в акцию X.
Вывод: вам не нужно искать активы с отрицательной корреляцией, чтобы воспользоваться плодами диверсификации! Вполне достаточно, чтобы корреляция была отлична от 1.0. Диверсификация может снизить риск ваших инвестиций при той же ожидаемой доходности или дать большую доходность при неизменном уровне риска.
Портфельная оптимизация
Давайте обобщим наш замечательный пример с двумя акциями на случай, когда мы составляем портфель из произвольного числа активов. При этом каждый актив обладает собственной ожидаемой доходностью и дисперсией.
Допустим, что нам известны ожидаемые доходности четырёх классов активов: акций, облигаций, инвестиционных фондов недвижимости (real estate investment trust, REIT) и золота. Также мы знаем стандартные отклонения и корреляции между активами. Эти значения приведены в таблице 1.4.
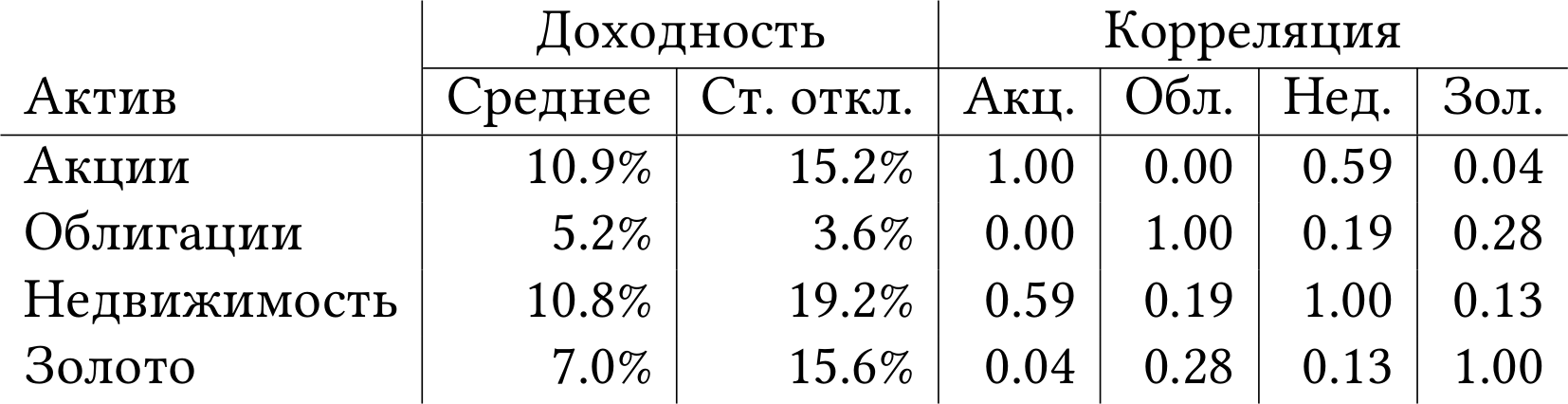
Таблица 1.4: Средние годовые доходности, стандартные отклонения и корреляции между классами активов. 1994–2020. Данные: [EF20].
Как видите, я использовал исторические данные, чтобы оценить параметры распределения будущих доходностей активов. Это довольно опасное занятие, потому что прошлое не предсказывает будущее. В идеале, я должен был бы нанять аналитика, который выдал бы мне ожидаемые будущие доходности исходя из научного прогноза, а не исходя из средней доходности в прошлом. К сожалению, редкий прогноз на финансовых рынках оказывается точнее, чем «будет как раньше». Впрочем, для нашей цели проиллюстрировать принцип диверсификации это не так важно.
Итак, вы — инвестор, который любит доходность и не любит дисперсию. Вам нужно распределить свой капитал между четырьмя активами. Какую пропорцию между акциями, облигациями, недвижимостью и золотом выбрать?
Разумно задать следующий вопрос: если вы хотите получить ожидаемую доходность, скажем 10%, то какой портфель (какая пропорция акций, облигаций, недвижимости и золота) обеспечат такую доходность? А если таких возможных портфелей несколько (что вполне возможно), то который из них будет наименее рискованным (дисперсия и стандартное отклонение будут меньше, чем у остальных портфелей с такой доходностью)?
Рисунок 1.3 отвечает на этот вопрос. Каждая точка на графике — это гипотетический портфель, который характеризуется стандартным отклонением (ось x) и ожидаемой доходностью (ось y). Для каждого уровня желаемой доходности я рассчитал (как — расскажу позже) оптимальный портфель, то есть портфель с наименьшим стандартным отклонением из всех портфелей с данной доходностью.
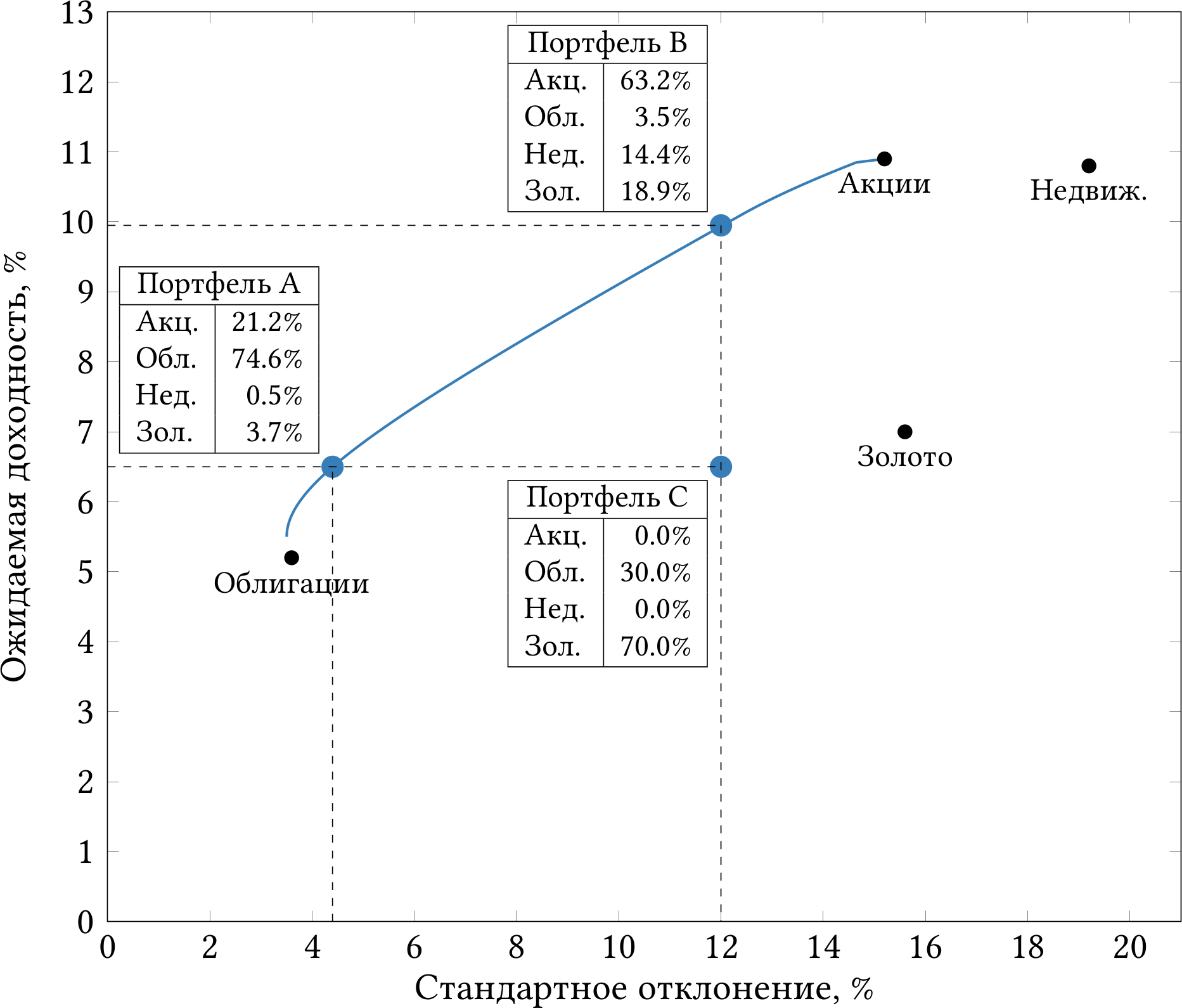
Рис. 1.3: Граница эффективности для портфелей, составленных из акций, облигаций, недвижимости и золота.
Синяя линия на графике — это так называемая граница эффективности (efficient frontier). Именно на ней лежат оптимальные портфели, имеющие минимальное стандартное отклонение при заданной доходности. Рациональный инвестор будет стремиться выбрать один из портфелей на этой линии, потому что любой другой портфель будет заведомо хуже.
Например, совершенно нет смысла выбирать портфель C, состоящий на 30% из облигаций и на 70% из золота. Этот портфель имеет ожидаемую доходность 6.5% при стандартном отклонении 12%. Однако раз уж вы согласны принять на себя риск в 12%, то за этот риск вы можете получить более высокую доходность — почти 10% в портфеле B (63.2% в акциях). С другой стороны, если вы готовы удовлетвориться ожидаемой доходностью 6.5%, то лучше выбрать менее рискованный портфель A (74.6% в облигациях), который имеет стандартное отклонение 4.4%.
Другими словами, вы всегда стремитесь выбрать портфель, который лежит выше (больше доходность) и левее (меньше риск). В какой-то момент вы упрётесь в границу эффективности и не сможете двигаться дальше — не получится заработать 15% при стандартном отклонении 4%. Очутившись на границе эффективности, вы можете гулять по ней либо вправо-вверх (больше риск, больше доходность), либо влево-вниз (ниже риск, ниже доходность). То, на каком из оптимальных портфелей на границе эффективности остановитесь именно вы, зависит от вашей личной чувствительности к риску.
Обратите внимание, что граница эффективности лежит выше или левее, чем отдельные активы — облигации, золото, недвижимость. Мы снова возвращаемся к идее диверсификации. Если вы держите все инвестиции в одном активе, то, скорее всего, вы могли бы получать такую же доходность при меньшем уровне риска, если бы диверсифицировались. Чаще всего на границе эффективности оказываются портфели, составленные из нескольких активов.
Рисунок 1.4 показывает, как изменяется состав оптимального портфеля по мере того, как вы движетесь по границе эффективности слева направо (от меньшего риска к большему риску). Вполне ожидаемо, наименее рискованные портфели состоят в основном из облигаций, а наиболее рискованные — из акций и недвижимости.
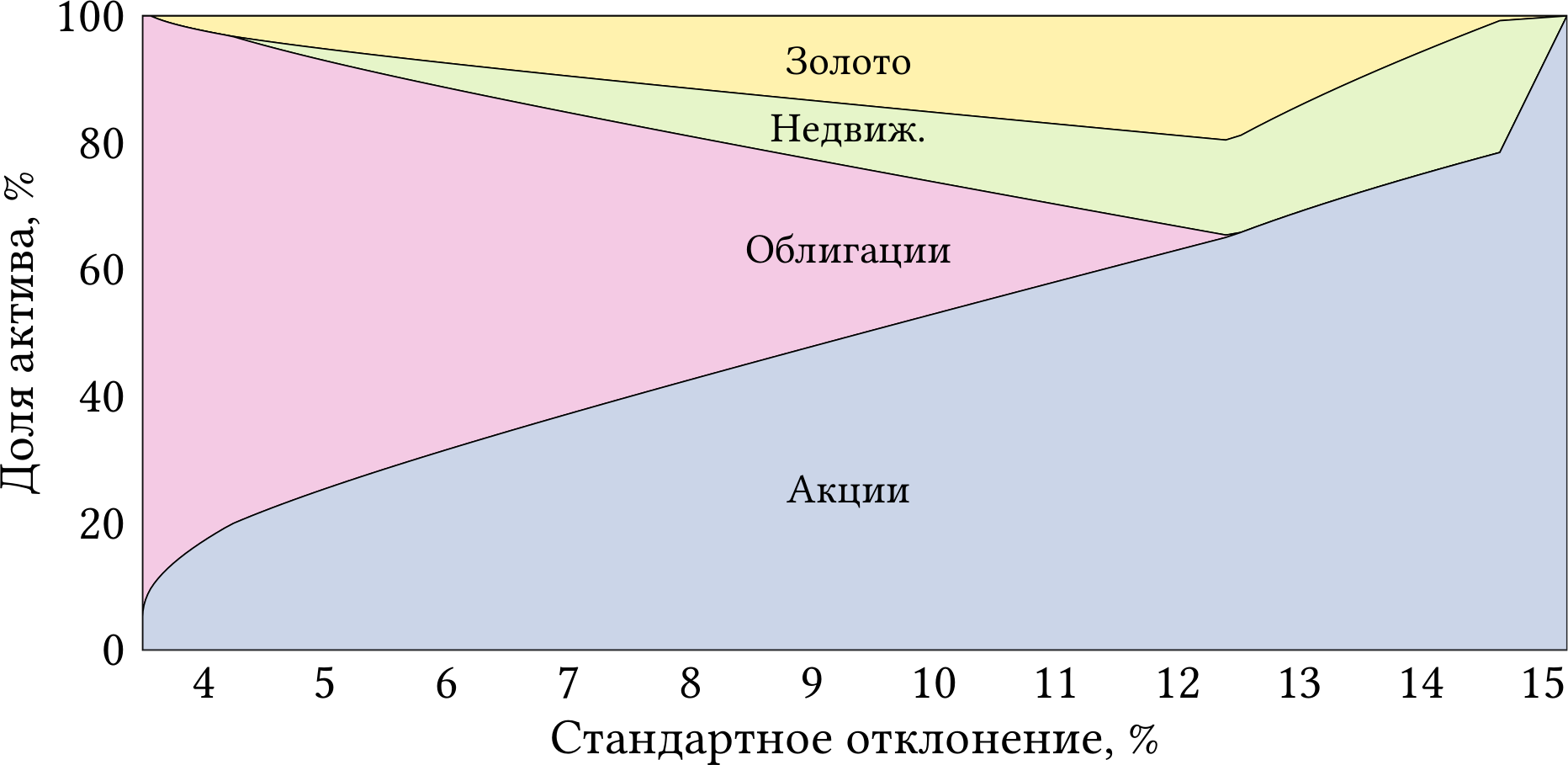
Рис. 1.4: Состав портфелей на границе эффективности.
В подтверждение тезиса о диверсификации, единственный оптимальный портфель, который состоит только из одного актива (акций) — это портфель с максимальной доходностью и максимальным риском. Это ожидаемо, потому что в условии задачи именно акции имеют максимальную доходность 10.9%. Если хоть немного разбавить акции другим активом с меньшей доходностью, то общая доходность портфеля упадёт. Так что инвестор, который желает выжать максимально возможную доходность, будет вынужден составить портфель только из акций.
Квадратичное программирование
В предыдущем разделе я обещал рассказать, как именно я посчитал оптимальные портфели. В этом разделе я выполню обещание и объясню, как формально поставить задачу выбора оптимального портфеля на языке математики. Если вам не очень интересны математические подробности, то вы можете смело перейти к следующему разделу. Незнание этих выкладок не помешает вам продолжить читать статью и извлечь из неё пользу.
Если вы всё ещё со мной, то, как говорил известный сатирик, наберите воздуха в грудь.
Итак, у нас есть n активов. Будущая доходность i-го актива — это случайная величина со средним μi и стандартным отклонением σi. Доходности i-го и j-го актива связаны корреляцией ρi,j.
Нас просят распределить единичный капитал между активами. Более формально, i-му активу нужно присвоить вес (долю в портфеле) xi. Потребуем, чтобы все веса xi были положительными (нельзя продать актив, которого у нас нет), а их сумма равнялась единице (мы должны распределить весь капитал без остатка).
Для начала введём несколько удобных матричных обозначений, то есть запишем параметры задачи в аккуратные прямоугольные таблицы.
Утверждается, что вопрос «какой портфель с ожидаемой доходностью r имеет наименьшую дисперсию?» можно формально записать в виде следующей задачи минимизации:
Вид формул (1.4) вызывает у разных людей противоположные эмоции. Например, человек, знакомый с теорией математической оптимизации, воскликнет: «Батюшки, да это же банальный QP! Стоило ли ради этого писать столько текста?»
Действительно, хорошая новость заключается в том, что человечество уже давно научилось решать задачи такого вида и даже дало им специальное название — квадратичное программирование (quadratic programming, QP) [CT06, ch. 7–8]. Почти для любого языка программирования, от C до Питона, найдётся готовая библиотека для решения этой задачи. Достаточно ничего не напутать и правильно составить матрицы μ, S и e, а дальше библиотека сама найдёт оптимальное решение. Совершенно не обязательно разбираться в том, какой алгоритм поиска решения крутится под капотом.
С другой стороны, у неподготовленного человека такая постановка задачи может вызвать ступор. Давайте пройдёмся по ней строчка за строчкой, чтобы убедиться, что в ней нет никакой тёмной магии.
Что такое x T Sx? Это компактная запись дисперсии портфеля, составленного с весами xi. Для наглядности можно расписать это выражение для случая двух активов (n = 2) и перемножить матрицы как нас учили на первом курсе, строка на столбец. Получится уже знакомая нам формула (1.3), связывающая дисперсию суммы с ковариацией:
Следовательно, если мы попросим алгоритм минимизировать значение x T Sx, то он постарается найти портфель (набор весов xi) с минимальной дисперсией.
Если не задать алгоритму оптимизации никаких ограничений, то он довольно быстро скажет вам, что портфель с минимальной дисперсией — это портфель с нулевыми весами. Действительно, если ничего не инвестировать, то и риска никакого не будет. Это не совсем то, что мы хотим, поэтому нам нужно добавить в задачу дополнительные ограничения (constraints).
Первое ограничение — это μ T x = r. По-русски, мы просим алгоритм рассматривать только те портфели, которые имеют ожидаемую доходность r. В самом деле, если расписать матричное умножение, то получится сумма μ1x1 +… + μnxn, то есть ожидаемая доходность портфеля.
Второе ограничение e T x = 1 можно записать как x1 +… + xn = 1. Мы говорим алгоритму, что корректное решение (набор весов xi) — это когда весь единичный капитал распределён между активами и ни один рубль не остался неинвестированным.
Наконец, третье ограничение x ≥ 0 просто говорит, что все веса xi должны быть неотрицательными (можно только покупать активы в портфель, но нельзя продавать).
Всё, заканчиваю стращать вас математикой. В сухом остатке, мы всегда можем найти оптимальный портфель, то есть портфель с минимальной дисперсией, для заданной ожидаемой доходности r. Для этого нужно составить несколько матриц и скормить их алгоритму квадратичного программирования.
В качестве исторической справки отмечу, что идея сформулировать задачу выбора портфеля как задачу поиска баланса между дисперсией и ожидаемой доходностью принадлежит Гарри Марковицу (Harry Markowitz) [Mar52]. Поэтому иногда эту задачу называют оптимизацией по Марковицу. Ещё одно название, которое вы можете встретить — современная портфельная теория (modern portfolio theory, MPT).
Отказ от ответственности
Мнение автора статьи может не совпадать с официальной позицией Deutsche Bank AG. Статья не является предложением или рекламой какой-либо услуги. Упоминание третьих сторон не предполагает одобрения или неодобрения. Автор и Deutsche Bank напоминают, что торговля на финансовых рынках сопряжена с риском, и не несут ответственности за возможные негативные последствия ваших личных инвестиционных решений.
Список литературы
[BKM14] Zvi Bodie, Alex Kane, and Alan J Marcus. Investments. 4th ed. McGraw-Hill Education, 2014. ISBN: 978-0-07-786167-4.
[Coc13] John H Cochrane. Consumption and Risk Premiums. University of Chicago. 2013.
[CT06] Gerard Cornuejols and Reha Tütüncü. Optimization methods in finance. Cambridge University Press, 2006. ISBN: 9780511258183.
[EF20] Silicon Cloud Technologies LLC. Portfolio Visualizer — Efficient Frontier. 2020.
[Mar52] Harry Markowitz. “Portfolio Selection”. In: The Journal of Finance 7.1 (1952), pp. 77–91.
Источник https://habr.com/ru/company/dbtc/blog/527050/
Источник
Источник
Источник