Обзор самых популярных алгоритмов машинного обучения
![]()
Существует такое понятие, как «No Free Lunch» теорема. Её суть заключается в том, что нет такого алгоритма, который был бы лучшим выбором для каждой задачи, что в особенности касается обучения с учителем.
Например, нельзя сказать, что нейронные сети всегда работают лучше, чем деревья решений, и наоборот. На эффективность алгоритмов влияет множество факторов вроде размера и структуры набора данных.
По этой причине приходится пробовать много разных алгоритмов, проверяя эффективность каждого на тестовом наборе данных, и затем выбирать лучший вариант. Само собой, нужно выбирать среди алгоритмов, соответствующих вашей задаче. Если проводить аналогию, то при уборке дома вы, скорее всего, будете использовать пылесос, метлу или швабру, но никак не лопату.
Piano , Казань, можно удалённо , По итогам собеседования
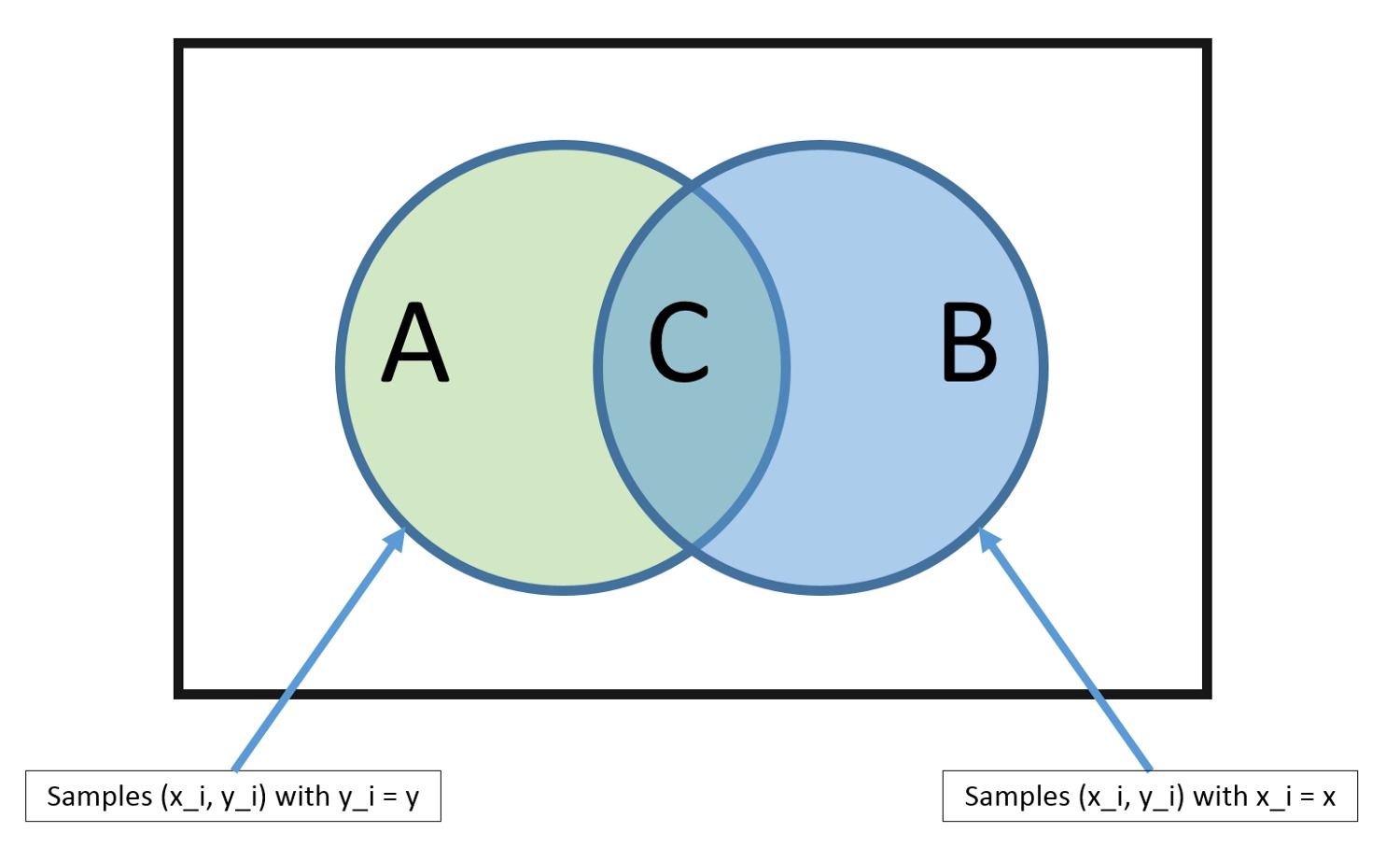
Алгоритмы машинного обучения можно описать как обучение целевой функции f , которая наилучшим образом соотносит входные переменные X и выходную переменную Y : Y = f(X) .
Мы не знаем, что из себя представляет функция f . Ведь если бы знали, то использовали бы её напрямую, а не пытались обучить с помощью различных алгоритмов.
Наиболее распространённой задачей в машинном обучении является предсказание значений Y для новых значений X . Это называется прогностическим моделированием, и наша цель — сделать как можно более точное предсказание.
Представляем вашему вниманию краткий обзор топ-10 популярных алгоритмов, используемых в машинном обучении.
1. Линейная регрессия
Линейная регрессия — пожалуй, один из наиболее известных и понятных алгоритмов в статистике и машинном обучении.
Прогностическое моделирование в первую очередь касается минимизации ошибки модели или, другими словами, как можно более точного прогнозирования. Мы будем заимствовать алгоритмы из разных областей, включая статистику, и использовать их в этих целях.
Линейную регрессию можно представить в виде уравнения, которое описывает прямую, наиболее точно показывающую взаимосвязь между входными переменными X и выходными переменными Y . Для составления этого уравнения нужно найти определённые коэффициенты B для входных переменных.
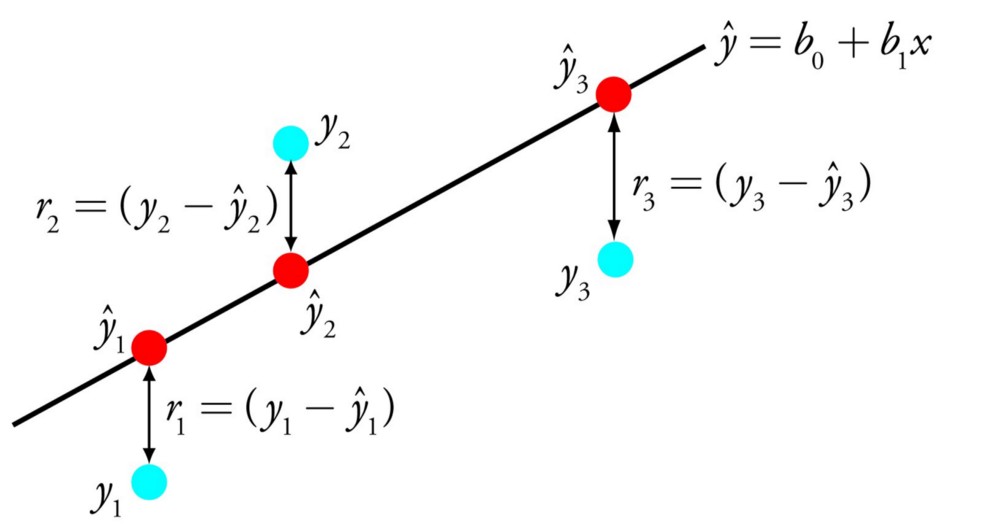
Например: Y = B0 + B1 * X
Зная X , мы должны найти Y , и цель линейной регрессии заключается в поиске значений коэффициентов B0 и B1 .
Для оценки регрессионной модели используются различные методы вроде линейной алгебры или метода наименьших квадратов.
Линейная регрессия существует уже более 200 лет, и за это время её успели тщательно изучить. Так что вот пара практических правил: уберите похожие (коррелирующие) переменные и избавьтесь от шума в данных, если это возможно. Линейная регрессия — быстрый и простой алгоритм, который хорошо подходит в качестве первого алгоритма для изучения.
2 . Логистическая регрессия
Логистическая регрессия — ещё один алгоритм, пришедший в машинное обучение прямиком из статистики. Её хорошо использовать для задач бинарной классификации (это задачи, в которых на выходе мы получаем один из двух классов).
Логистическая регрессия похожа на линейную тем, что в ней тоже требуется найти значения коэффициентов для входных переменных. Разница заключается в том, что выходное значение преобразуется с помощью нелинейной или логистической функции.
Логистическая функция выглядит как большая буква S и преобразовывает любое значение в число в пределах от 0 до 1. Это весьма полезно, так как мы можем применить правило к выходу логистической функции для привязки к 0 и 1 (например, если результат функции меньше 0.5, то на выходе получаем 1) и предсказания класса.
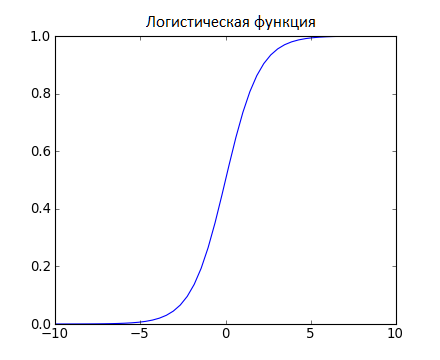
Благодаря тому, как обучается модель, предсказания логистической регрессии можно использовать для отображения вероятности принадлежности образца к классу 0 или 1. Это полезно в тех случаях, когда нужно иметь больше обоснований для прогнозирования.
Как и в случае с линейной регрессией, логистическая регрессия выполняет свою задачу лучше, если убрать лишние и похожие переменные. Модель логистической регрессии быстро обучается и хорошо подходит для задач бинарной классификации.
3. Линейный дискриминантный анализ (LDA)
Логистическая регрессия используется, когда нужно отнести образец к одному из двух классов. Если классов больше, чем два, то лучше использовать алгоритм LDA (Linear discriminant analysis).
Представление LDA довольно простое. Оно состоит из статистических свойств данных, рассчитанных для каждого класса. Для каждой входной переменной это включает:
- Среднее значение для каждого класса;
- Дисперсию, рассчитанную по всем классам.
Предсказания производятся путём вычисления дискриминантного значения для каждого класса и выбора класса с наибольшим значением. Предполагается, что данные имеют нормальное распределение, поэтому перед началом работы рекомендуется удалить из данных аномальные значения. Это простой и эффективный алгоритм для задач классификации.
4. Деревья принятия решений
Дерево решений можно представить в виде двоичного дерева, знакомого многим по алгоритмам и структурам данных. Каждый узел представляет собой входную переменную и точку разделения для этой переменной (при условии, что переменная — число).
Листовые узлы — это выходная переменная, которая используется для предсказания. Предсказания производятся путём прохода по дереву к листовому узлу и вывода значения класса на этом узле.
Деревья быстро обучаются и делают предсказания. Кроме того, они точны для широкого круга задач и не требуют особой подготовки данных.
5 . Наивный Байесовский классификатор
Наивный Байес — простой, но удивительно эффективный алгоритм.
Модель состоит из двух типов вероятностей, которые рассчитываются с помощью тренировочных данных:
- Вероятность каждого класса.
- Условная вероятность для каждого класса при каждом значении x.
После расчёта вероятностной модели её можно использовать для предсказания с новыми данными при помощи теоремы Байеса. Если у вас вещественные данные, то, предполагая нормальное распределение, рассчитать эти вероятности не составляет особой сложности.
Наивный Байес называется наивным, потому что алгоритм предполагает, что каждая входная переменная независимая. Это сильное предположение, которое не соответствует реальным данным. Тем не менее данный алгоритм весьма эффективен для целого ряда сложных задач вроде классификации спама или распознавания рукописных цифр.
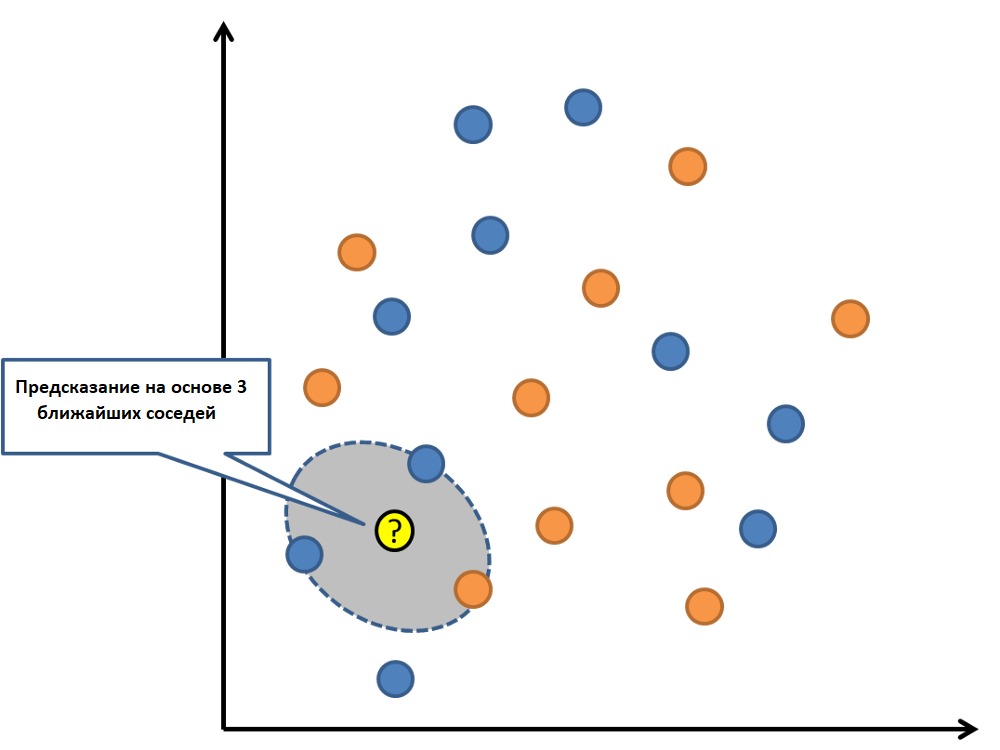
6. K-ближайших соседей (KNN)
К-ближайших соседей — очень простой и очень эффективный алгоритм. Модель KNN (K-nearest neighbors) представлена всем набором тренировочных данных. Довольно просто, не так ли?
Предсказание для новой точки делается путём поиска K ближайших соседей в наборе данных и суммирования выходной переменной для этих K экземпляров.
Вопрос лишь в том, как определить сходство между экземплярами данных. Если все признаки имеют один и тот же масштаб (например, сантиметры), то самый простой способ заключается в использовании евклидова расстояния — числа, которое можно рассчитать на основе различий с каждой входной переменной.
KNN может потребовать много памяти для хранения всех данных, но зато быстро сделает предсказание. Также обучающие данные можно обновлять, чтобы предсказания оставались точными с течением времени.
Идея ближайших соседей может плохо работать с многомерными данными (множество входных переменных), что негативно скажется на эффективности алгоритма при решении задачи. Это называется проклятием размерности. Иными словами, стоит использовать лишь наиболее важные для предсказания переменные.
7 . Сети векторного квантования (LVQ)
Недостаток KNN заключается в том, что нужно хранить весь тренировочный набор данных. Если KNN хорошо себя показал, то есть смысл попробовать алгоритм LVQ (Learning vector quantization), который лишён этого недостатка.
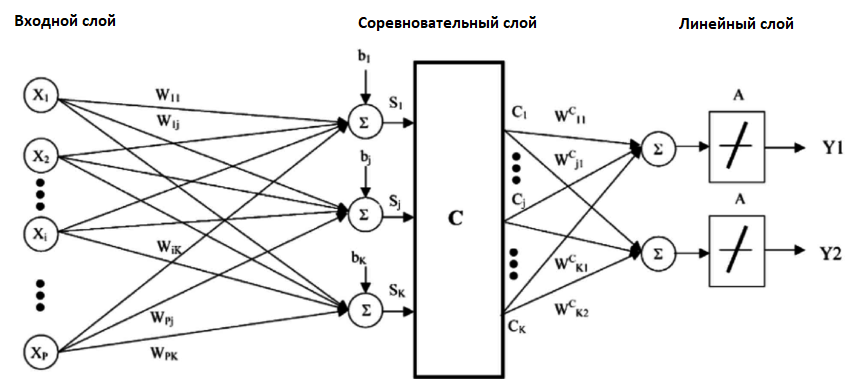
LVQ представляет собой набор кодовых векторов. Они выбираются в начале случайным образом и в течение определённого количества итераций адаптируются так, чтобы наилучшим образом обобщить весь набор данных. После обучения эти вектора могут использоваться для предсказания так же, как это делается в KNN. Алгоритм ищет ближайшего соседа (наиболее подходящий кодовый вектор) путём вычисления расстояния между каждым кодовым вектором и новым экземпляром данных. Затем для наиболее подходящего вектора в качестве предсказания возвращается класс (или число в случае регрессии). Лучшего результата можно достичь, если все данные будут находиться в одном диапазоне, например от 0 до 1.
8. Метод опорных векторов (SVM)
Метод опорных векторов, вероятно, один из наиболее популярных и обсуждаемых алгоритмов машинного обучения.
Гиперплоскость — это линия, разделяющая пространство входных переменных. В методе опорных векторов гиперплоскость выбирается так, чтобы наилучшим образом разделять точки в плоскости входных переменных по их классу: 0 или 1. В двумерной плоскости это можно представить как линию, которая полностью разделяет точки всех классов. Во время обучения алгоритм ищет коэффициенты, которые помогают лучше разделять классы гиперплоскостью.
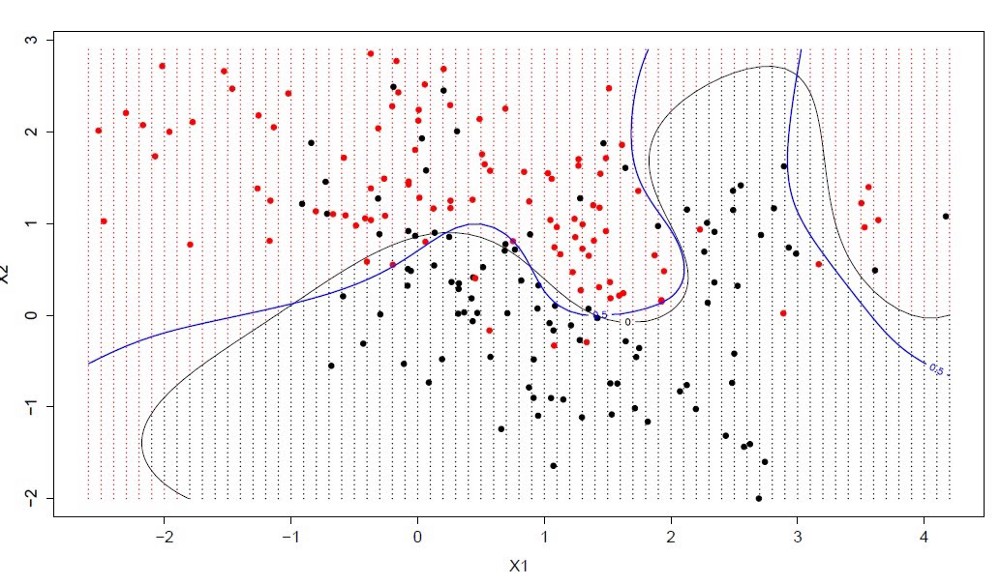
Расстояние между гиперплоскостью и ближайшими точками данных называется разницей. Лучшая или оптимальная гиперплоскость, разделяющая два класса, — это линия с наибольшей разницей. Только эти точки имеют значение при определении гиперплоскости и при построении классификатора. Эти точки называются опорными векторами. Для определения значений коэффициентов, максимизирующих разницу, используются специальные алгоритмы оптимизации.
Метод опорных векторов, наверное, один из самых эффективных классических классификаторов, на который определённо стоит обратить внимание.
9 . Бэггинг и случайный лес
Случайный лес — очень популярный и эффективный алгоритм машинного обучения. Это разновидность ансамблевого алгоритма, называемого бэггингом.
Бутстрэп является эффективным статистическим методом для оценки какой-либо величины вроде среднего значения. Вы берёте множество подвыборок из ваших данных, считаете среднее значение для каждой, а затем усредняете результаты для получения лучшей оценки действительного среднего значения.
В бэггинге используется тот же подход, но для оценки всех статистических моделей чаще всего используются деревья решений. Тренировочные данные разбиваются на множество выборок, для каждой из которой создаётся модель. Когда нужно сделать предсказание, то его делает каждая модель, а затем предсказания усредняются, чтобы дать лучшую оценку выходному значению.
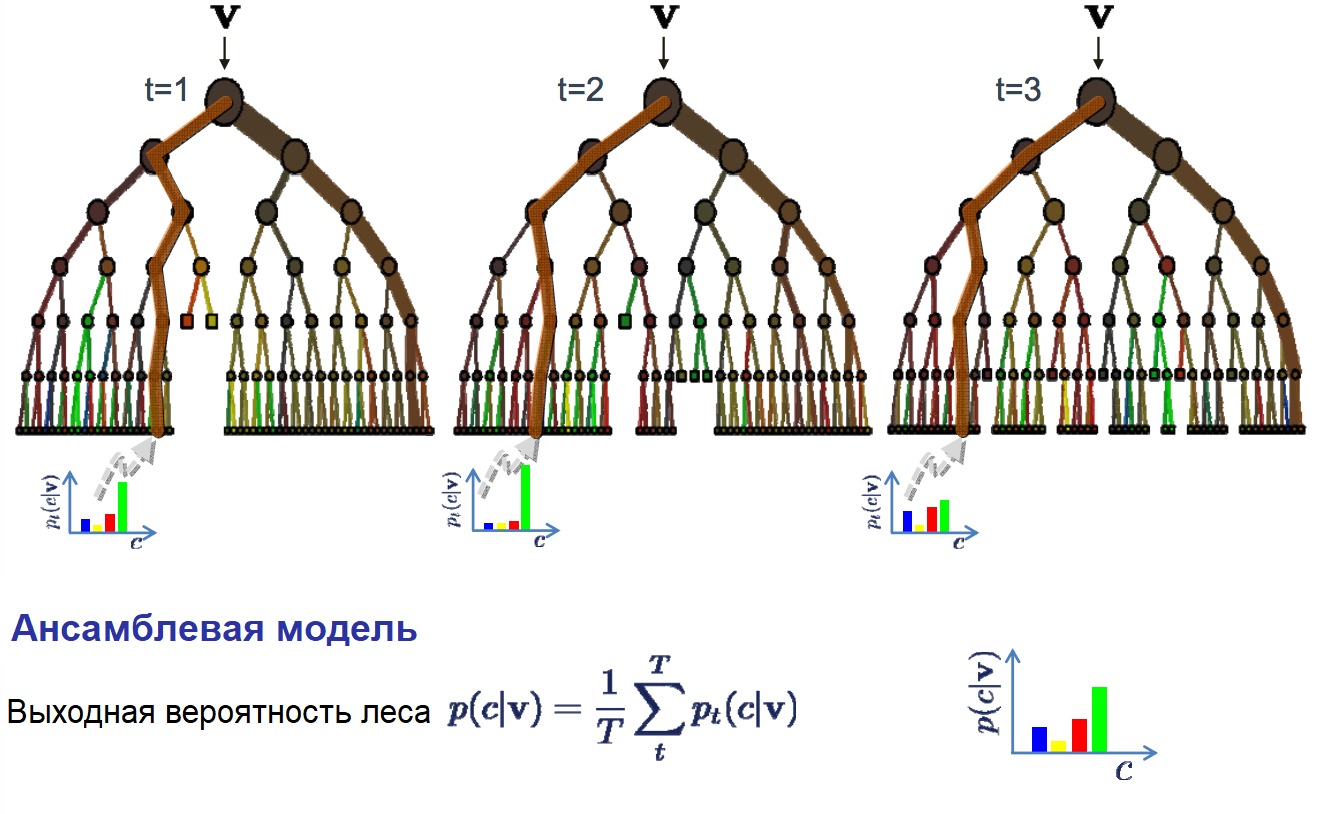
В алгоритме случайного леса для всех выборок из тренировочных данных строятся деревья решений. При построении деревьев для создания каждого узла выбираются случайные признаки. В отдельности полученные модели не очень точны, но при их объединении качество предсказания значительно улучшается.
Если алгоритм с высокой дисперсией, например, деревья решений, показывает хороший результат на ваших данных, то этот результат зачастую можно улучшить, применив бэггинг.
10 . Бустинг и AdaBoost
Бустинг — это семейство ансамблевых алгоритмов, суть которых заключается в создании сильного классификатора на основе нескольких слабых. Для этого сначала создаётся одна модель, затем другая модель, которая пытается исправить ошибки в первой. Модели добавляются до тех пор, пока тренировочные данные не будут идеально предсказываться или пока не будет превышено максимальное количество моделей.
AdaBoost был первым действительно успешным алгоритмом бустинга, разработанным для бинарной классификации. Именно с него лучше всего начинать знакомство с бустингом. Современные методы вроде стохастического градиентного бустинга основываются на AdaBoost.
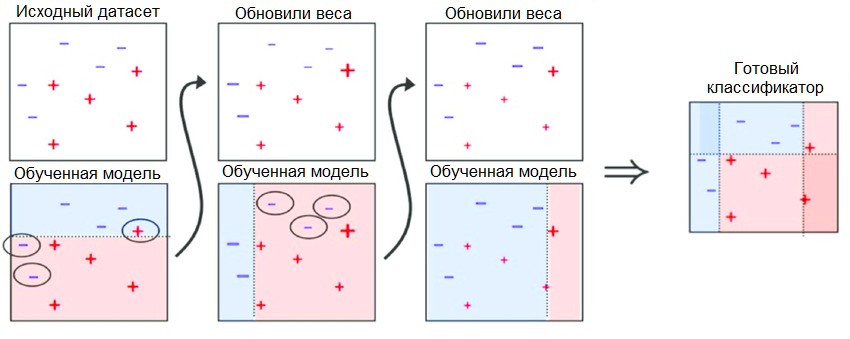
AdaBoost используют вместе с короткими деревьями решений. После создания первого дерева проверяется его эффективность на каждом тренировочном объекте, чтобы понять, сколько внимания должно уделить следующее дерево всем объектам. Тем данным, которые сложно предсказать, даётся больший вес, а тем, которые легко предсказать, — меньший. Модели создаются последовательно одна за другой, и каждая из них обновляет веса для следующего дерева. После построения всех деревьев делаются предсказания для новых данных, и эффективность каждого дерева определяется тем, насколько точным оно было на тренировочных данных.
Так как в этом алгоритме большое внимание уделяется исправлению ошибок моделей, важно, чтобы в данных отсутствовали аномалии.
Пара слов напоследок
Когда новички видят всё разнообразие алгоритмов, они задаются стандартным вопросом: «А какой следует использовать мне?» Ответ на этот вопрос зависит от множества факторов:
- Размер, качество и характер данных;
- Доступное вычислительное время;
- Срочность задачи;
- Что вы хотите делать с данными.
Даже опытный data scientist не скажет, какой алгоритм будет работать лучше, прежде чем попробует несколько вариантов. Существует множество других алгоритмов машинного обучения, но приведённые выше — наиболее популярные. Если вы только знакомитесь с машинным обучением, то они будут хорошей отправной точкой.
Машинное обучение для людей — разбираемся простыми словами
Машинное обучение — как секс в старших классах. Все говорят о нем по углам, единицы понимают, а занимается только препод. Статьи о машинном обучении делятся на два типа: это либо трёхтомники с формулами и теоремами, которые я ни разу не смог дочитать даже до середины, либо сказки об искусственном интеллекте, профессиях будущего и волшебных дата-саентистах.
Решил сам написать пост, которого мне не хватало. Большое введение для тех, кто хочет наконец разобраться в машинном обучении — простым языком, без формул-теорем, зато с примерами реальных задач и их решений.

Зачем обучать машины

Снова разберём на Олегах.
Предположим, Олег хочет купить автомобиль и считает сколько денег ему нужно для этого накопить. Он пересмотрел десяток объявлений в интернете и увидел, что новые автомобили стоят около $20 000, годовалые — примерно $19 000, двухлетние — $18 000 и так далее.
В уме Олег-аналитик выводит формулу: адекватная цена автомобиля начинается от $20 000 и падает на $1000 каждый год, пока не упрётся в $10 000.
Олег сделал то, что в машинном обучении называют регрессией — предсказал цену по известным данным. Люди делают это постоянно, когда считают почём продать старый айфон или сколько шашлыка взять на дачу (моя формула — полкило на человека в сутки).
Да, было бы удобно иметь формулу под каждую проблему на свете. Но взять те же цены на автомобили: кроме пробега есть десятки комплектаций, разное техническое состояние, сезонность спроса и еще столько неочевидных факторов, которые Олег, даже при всём желании, не учел бы в голове.
Люди тупы и ленивы — надо заставить вкалывать роботов. Пусть машина посмотрит на наши данные, найдёт в них закономерности и научится предсказывать для нас ответ. Самое интересное, что в итоге она стала находить даже такие закономерности, о которых люди не догадывались.
Так родилось машинное обучение.
Три составляющие обучения
Цель машинного обучения — предсказать результат по входным данным. Чем разнообразнее входные данные, тем проще машине найти закономерности и тем точнее результат.
Итак, если мы хотим обучить машину, нам нужны три вещи:
Данные Хотим определять спам — нужны примеры спам-писем, предсказывать курс акций — нужна история цен, узнать интересы пользователя — нужны его лайки или посты. Данных нужно как можно больше. Десятки тысяч примеров — это самый злой минимум для отчаянных.

Данные собирают как могут. Кто-то вручную — получается дольше, меньше, зато без ошибок. Кто-то автоматически — просто сливает машине всё, что нашлось, и верит в лучшее. Самые хитрые, типа гугла, используют своих же пользователей для бесплатной разметки. Вспомните ReCaptcha, которая иногда требует «найти на фотографии все дорожные знаки» — это оно и есть.
За хорошими наборами данных (датасетами) идёт большая охота. Крупные компании, бывает, раскрывают свои алгоритмы, но датасеты — крайне редко.
Признаки Мы называем их фичами (features), так что ненавистникам англицизмов придётся страдать. Фичи, свойства, характеристики, признаки — ими могут быть пробег автомобиля, пол пользователя, цена акций, даже счетчик частоты появления слова в тексте может быть фичей.
Машина должна знать, на что ей конкретно смотреть. Хорошо, когда данные просто лежат в табличках — названия их колонок и есть фичи. А если у нас сто гигабайт картинок с котами? Когда признаков много, модель работает медленно и неэффективно. Зачастую отбор правильных фич занимает больше времени, чем всё остальное обучение. Но бывают и обратные ситуации, когда кожаный мешок сам решает отобрать только «правильные» на его взгляд признаки и вносит в модель субъективность — она начинает дико врать.
Алгоритм Одну задачу можно решить разными методами примерно всегда. От выбора метода зависит точность, скорость работы и размер готовой модели. Но есть один нюанс: если данные говно, даже самый лучший алгоритм не поможет. Не зацикливайтесь на процентах, лучше соберите побольше данных.

Обучение vs Интеллект
Однажды в одном хипстерском издании я видел статью под заголовком «Заменят ли нейросети машинное обучение». Пиарщики в своих пресс-релизах обзывают «искусственным интеллектом» любую линейную регрессию, с которой уже дети во дворе играют. Объясняю разницу на картинке, раз и навсегда.

Искусственный интеллект — название всей области, как биология или химия.
Машинное обучение — это раздел искусственного интеллекта. Важный, но не единственный.
Нейросети — один из видов машинного обучения. Популярный, но есть и другие, не хуже.
Глубокое обучение — архитектура нейросетей, один из подходов к их построению и обучению. На практике сегодня мало кто отличает, где глубокие нейросети, а где не очень. Говорят название конкретной сети и всё.
Сравнивать можно только вещи одного уровня, иначе получается полный буллщит типа «что лучше: машина или колесо?» Не отождествляйте термины без причины, чтобы не выглядеть дурачком.
Вот что машины сегодня умеют, а что не под силу даже самым обученным.
| Машина может | Машина не может |
|---|---|
| Предсказывать | Создавать новое |
| Запоминать | Резко поумнеть |
| Воспроизводить | Выйти за рамки задачи |
| Выбирать лучшее | Убить всех людей |
Карта мира машинного обучения
Лень читать лонгрид — повтыкайте хотя бы в картинку, будет полезно.

Думаю потом нарисовать полноценную настенную карту со стрелочками и объяснениями, что где используется, если статья зайдёт.
И да. Классифицировать алгоритмы можно десятком способов. Я выбрал этот, потому что он мне кажется самым удобным для повествования. Надо понимать, что не бывает так, чтобы задачу решал только один метод. Я буду упоминать известные примеры применений, но держите в уме, что «сын маминой подруги» всё это может решить нейросетями.
Начну с базового обзора. Сегодня в машинном обучении есть всего четыре основных направления.

Часть 1. Классическое обучение
Первые алгоритмы пришли к нам из чистой статистики еще в 1950-х. Они решали формальные задачи — искали закономерности в циферках, оценивали близость точек в пространстве и вычисляли направления.
Сегодня на классических алгоритмах держится добрая половина интернета. Когда вы встречаете блок «Рекомендованные статьи» на сайте, или банк блокирует все ваши деньги на карточке после первой же покупки кофе за границей — это почти всегда дело рук одного из этих алгоритмов.
Да, крупные корпорации любят решать все проблемы нейросетями. Потому что лишние 2% точности для них легко конвертируются в дополнительные 2 миллиарда прибыли. Остальным же стоит включать голову. Когда задача решаема классическими методами, дешевле реализовать сколько-нибудь полезную для бизнеса систему на них, а потом думать об улучшениях. А если вы не решили задачу, то не решить её на 2% лучше вам не особо поможет.
Знаю несколько смешных историй, когда команда три месяца переписывала систему рекомендаций интернет-магазина на более точный алгоритм, и только потом понимала, что покупатели вообще ей не пользуются. Большая часть просто приходит из поисковиков.
При всей своей популярности, классические алгоритмы настолько просты, что их легко объяснить даже ребёнку. Сегодня они как основы арифметики — пригождаются постоянно, но некоторые всё равно стали их забывать.

Обучение с учителем
Классическое обучение любят делить на две категории — с учителем и без. Часто можно встретить их английские наименования — Supervised и Unsupervised Learning.
В первом случае у машины есть некий учитель, который говорит ей как правильно. Рассказывает, что на этой картинке кошка, а на этой собака. То есть учитель уже заранее разделил (разметил) все данные на кошек и собак, а машина учится на конкретных примерах.
В обучении без учителя, машине просто вываливают кучу фотографий животных на стол и говорят «разберись, кто здесь на кого похож». Данные не размечены, у машины нет учителя, и она пытается сама найти любые закономерности. Об этих методах поговорим ниже.
Очевидно, что с учителем машина обучится быстрее и точнее, потому в боевых задачах его используют намного чаще. Эти задачи делятся на два типа: классификация — предсказание категории объекта, и регрессия — предсказание места на числовой прямой.
Классификация

«Разделяет объекты по заранее известному признаку. Носки по цветам, документы по языкам, музыку по жанрам»
Сегодня используют для:
- Спам-фильтры
- Определение языка
- Поиск похожих документов
- Анализ тональности
- Распознавание рукописных букв и цифр
- Определение подозрительных транзакций
Здесь и далее в комментах можно дополнять эти блоки. Приводите свои примеры задач, областей и алгоритмов, потому что описанные мной взяты из субъективного опыта.
Классификация вещей — самая популярная задача во всём машинном обучении. Машина в ней как ребёнок, который учится раскладывать игрушки: роботов в один ящик, танки в другой. Опа, а если это робот-танк? Штош, время расплакаться и выпасть в ошибку.
Старый доклад Бобука про повышение конверсии лендингов с помощью SVM
Для классификации всегда нужен учитель — размеченные данные с признаками и категориями, которые машина будет учиться определять по этим признакам. Дальше классифицировать можно что угодно: пользователей по интересам — так делают алгоритмические ленты, статьи по языкам и тематикам — важно для поисковиков, музыку по жанрам — вспомните плейлисты Спотифая и Яндекс.Музыки, даже письма в вашем почтовом ящике.
Раньше все спам-фильтры работали на алгоритме Наивного Байеса. Машина считала сколько раз слово «виагра» встречается в спаме, а сколько раз в нормальных письмах. Перемножала эти две вероятности по формуле Байеса, складывала результаты всех слов и бац, всем лежать, у нас машинное обучение!

Позже спамеры научились обходить фильтр Байеса, просто вставляя в конец письма много слов с «хорошими» рейтингами. Метод получил ироничное название Отравление Байеса, а фильтровать спам стали другими алгоритмами. Но метод навсегда остался в учебниках как самый простой, красивый и один из первых практически полезных.
Возьмем другой пример полезной классификации. Вот берёте вы кредит в банке. Как банку удостовериться, вернёте вы его или нет? Точно никак, но у банка есть тысячи профилей других людей, которые уже брали кредит до вас. Там указан их возраст, образование, должность, уровень зарплаты и главное — кто из них вернул кредит, а с кем возникли проблемы.
Да, все догадались, где здесь данные и какой надо предсказать результат. Обучим машину, найдём закономерности, получим ответ — вопрос не в этом. Проблема в том, что банк не может слепо доверять ответу машины, без объяснений. Вдруг сбой, злые хакеры или бухой админ решил скриптик исправить.
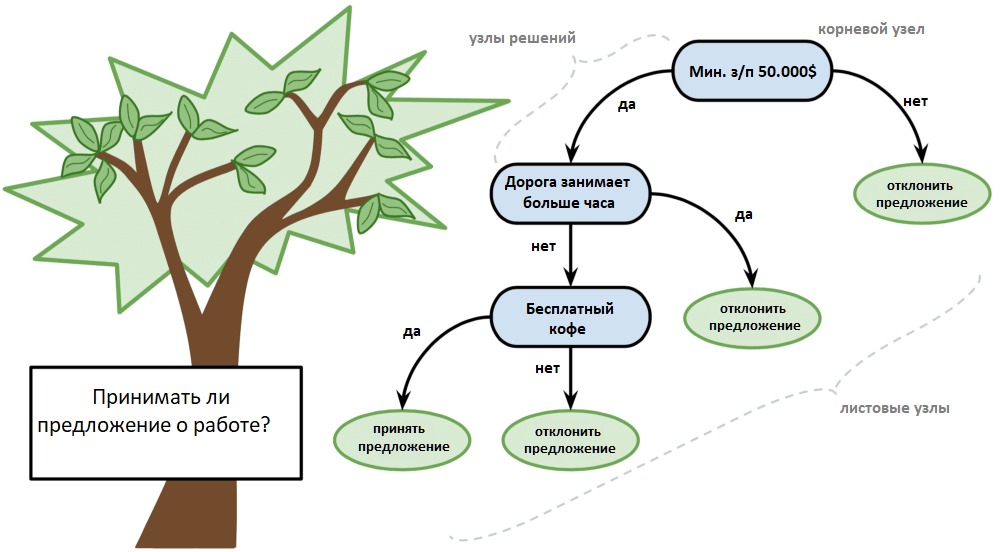
Для этой задачи придумали Деревья Решений. Машина автоматически разделяет все данные по вопросам, ответы на которые «да» или «нет». Вопросы могут быть не совсем адекватными с точки зрения человека, например «зарплата заёмщика больше, чем 25934 рубля?», но машина придумывает их так, чтобы на каждом шаге разбиение было самым точным.
Так получается дерево вопросов. Чем выше уровень, тем более общий вопрос. Потом даже можно загнать их аналитикам, и они навыдумывают почему так.
Деревья нашли свою нишу в областях с высокой ответственностью: диагностике, медицине, финансах.
Два самых популярных алгоритма построения деревьев — CART и C4.5.
В чистом виде деревья сегодня используют редко, но вот их ансамбли (о которых будет ниже) лежат в основе крупных систем и зачастую уделывают даже нейросети. Например, когда вы задаете вопрос Яндексу, именно толпа глупых деревьев бежит ранжировать вам результаты.

Но самым популярным методом классической классификации заслуженно является Метод Опорных Векторов (SVM). Им классифицировали уже всё: виды растений, лица на фотографиях, документы по тематикам, даже странных Playboy-моделей. Много лет он был главным ответом на вопрос «какой бы мне взять классификатор».
Идея SVM по своей сути проста — он ищет, как так провести две прямые между категориями, чтобы между ними образовался наибольший зазор. На картинке видно нагляднее:

У классификации есть полезная обратная сторона — поиск аномалий. Когда какой-то признак объекта сильно не вписывается в наши классы, мы ярко подсвечиваем его на экране. Сейчас так делают в медицине: компьютер подсвечивает врачу все подозрительные области МРТ или выделяет отклонения в анализах. На биржах таким же образом определяют нестандартных игроков, которые скорее всего являются инсайдерами. Научив компьютер «как правильно», мы автоматически получаем и обратный классификатор — как неправильно.
Сегодня для классификации всё чаще используют нейросети, ведь по сути их для этого и изобрели.
Правило буравчика такое: сложнее данные — сложнее алгоритм. Для текста, цифр, табличек я бы начинал с классики. Там модели меньше, обучаются быстрее и работают понятнее. Для картинок, видео и другой непонятной бигдаты — сразу смотрел бы в сторону нейросетей.
Лет пять назад еще можно было встретить классификатор лиц на SVM, но сегодня под эту задачу сотня готовых сеток по интернету валяются, чо бы их не взять. А вот спам-фильтры как на SVM писали, так и не вижу смысла останавливаться.
Регрессия

«Нарисуй линию вдоль моих точек. Да, это машинное обучение»
Сегодня используют для:
- Прогноз стоимости ценных бумаг
- Анализ спроса, объема продаж
- Медицинские диагнозы
- Любые зависимости числа от времени
Регрессия — та же классификация, только вместо категории мы предсказываем число. Стоимость автомобиля по его пробегу, количество пробок по времени суток, объем спроса на товар от роста компании и.т.д. На регрессию идеально ложатся любые задачи, где есть зависимость от времени.
Регрессию очень любят финансисты и аналитики, она встроена даже в Excel. Внутри всё работает, опять же, банально: машина тупо пытается нарисовать линию, которая в среднем отражает зависимость. Правда, в отличии от человека с фломастером и вайтбордом, делает она это математически точно — считая среднее расстояние до каждой точки и пытаясь всем угодить.

Когда регрессия рисует прямую линию, её называют линейной, когда кривую — полиномиальной. Это два основных вида регрессии, дальше уже начинаются редкоземельные методы. Но так как в семье не без урода, есть Логистическая Регрессия, которая на самом деле не регрессия, а метод классификации, от чего у всех постоянно путаница. Не делайте так.
Схожесть регрессии и классификации подтверждается еще и тем, что многие классификаторы, после небольшого тюнинга, превращаются в регрессоры. Например, мы можем не просто смотреть к какому классу принадлежит объект, а запоминать, насколько он близок — и вот, у нас регрессия.
Для желающих понять это глубже, но тоже простыми словами, рекомендую цикл статей Machine Learning for Humans
Обучение без учителя
Обучение без учителя (Unsupervised Learning) было изобретено позже, аж в 90-е, и на практике используется реже. Но бывают задачи, где у нас просто нет выбора.
Размеченные данные, как я сказал, дорогая редкость. Но что делать если я хочу, например, написать классификатор автобусов — идти на улицу руками фотографировать миллион сраных икарусов и подписывать где какой? Так и жизнь вся пройдёт, а у меня еще игры в стиме не пройдены.
Когда нет разметки, есть надежда на капитализм, социальное расслоение и миллион китайцев из сервисов типа Яндекс.Толока, которые готовы делать для вас что угодно за пять центов. Так обычно и поступают на практике. А вы думали где Яндекс берёт все свои крутые датасеты?
Либо, можно попробовать обучение без учителя. Хотя, честно говоря, из своей практики я не помню чтобы где-то оно сработало хорошо.
Обучение без учителя, всё же, чаще используют как метод анализа данных, а не как основной алгоритм. Специальный кожаный мешок с дипломом МГУ вбрасывает туда кучу мусора и наблюдает. Кластеры есть? Зависимости появились? Нет? Ну штош, продолжай, труд освобождает. Тыж хотел работать в датасаенсе.
Кластеризация

«Разделяет объекты по неизвестному признаку. Машина сама решает как лучше»
Сегодня используют для:
- Сегментация рынка (типов покупателей, лояльности)
- Объединение близких точек на карте
- Сжатие изображений
- Анализ и разметки новых данных
- Детекторы аномального поведения
Кластеризация — это классификация, но без заранее известных классов. Она сама ищет похожие объекты и объединяет их в кластеры. Количество кластеров можно задать заранее или доверить это машине. Похожесть объектов машина определяет по тем признакам, которые мы ей разметили — у кого много схожих характеристик, тех давай в один класс.
Отличный пример кластеризации — маркеры на картах в вебе. Когда вы ищете все крафтовые бары в Москве, движку приходится группировать их в кружочки с циферкой, иначе браузер зависнет в потугах нарисовать миллион маркеров.
Более сложные примеры кластеризации можно вспомнить в приложениях iPhoto или Google Photos, которые находят лица людей на фотографиях и группируют их в альбомы. Приложение не знает как зовут ваших друзей, но может отличить их по характерным чертам лица. Типичная кластеризация.
Правда для начала им приходится найти эти самые «характерные черты», а это уже только с учителем.
Сжатие изображений — еще одна популярная проблема. Сохраняя картинку в PNG, вы можете установить палитру, скажем, в 32 цвета. Тогда кластеризация найдёт все «примерно красные» пиксели изображения, высчитает из них «средний красный по больнице» и заменит все красные на него. Меньше цветов — меньше файл.
Проблема только, как быть с цветами типа Cyan ◼︎ — вот он ближе к зеленому или синему? Тут нам поможет популярный алгоритм кластеризации — Метод К-средних (K-Means). Мы случайным образом бросаем на палитру цветов наши 32 точки, обзывая их центроидами. Все остальные точки относим к ближайшему центроиду от них — получаются как бы созвездия из самых близких цветов. Затем двигаем центроид в центр своего созвездия и повторяем пока центроиды не перестанут двигаться. Кластеры обнаружены, стабильны и их ровно 32 как и надо было.

Искать центроиды удобно и просто, но в реальных задачах кластеры могут быть совсем не круглой формы. Вот вы геолог, которому нужно найти на карте схожие по структуре горные породы — ваши кластеры не только будут вложены друг в друга, но вы ещё и не знаете сколько их вообще получится.
Хитрым задачам — хитрые методы. DBSCAN, например. Он сам находит скопления точек и строит вокруг кластеры. Его легко понять, если представить, что точки — это люди на площади. Находим трёх любых близко стоящих человека и говорим им взяться за руки. Затем они начинают брать за руку тех, до кого могут дотянуться. Так по цепочке, пока никто больше не сможет взять кого-то за руку — это и будет первый кластер. Повторяем, пока не поделим всех. Те, кому вообще некого брать за руку — это выбросы, аномалии. В динамике выглядит довольно красиво:
Как и классификация, кластеризация тоже может использоваться как детектор аномалий. Поведение пользователя после регистрации резко отличается от нормального? Заблокировать его и создать тикет саппорту, чтобы проверили бот это или нет. При этом нам даже не надо знать, что есть «нормальное поведение» — мы просто выгружаем все действия пользователей в модель, и пусть машина сама разбирается кто тут нормальный.
Работает такой подход, по сравнению с классификацией, не очень. Но за спрос не бьют, вдруг получится.
Уменьшение Размерности (Обобщение)

«Собирает конкретные признаки в абстракции более высокого уровня»
Сегодня используют для:
- Рекомендательные Системы (★)
- Красивые визуализации
- Определение тематики и поиска похожих документов
- Анализ фейковых изображений
- Риск-менеджмент
Изначально это были методы хардкорных Data Scientist’ов, которым сгружали две фуры цифр и говорили найти там что-нибудь интересное. Когда просто строить графики в экселе уже не помогало, они придумали напрячь машины искать закономерности вместо них. Так у них появились методы, которые назвали Dimension Reduction или Feature Learning.
Для нас практическая польза их методов в том, что мы можем объединить несколько признаков в один и получить абстракцию. Например, собаки с треугольными ушами, длинными носами и большими хвостами соединяются в полезную абстракцию «овчарки». Да, мы теряем информацию о конкретных овчарках, но новая абстракция всяко полезнее этих лишних деталей. Плюс, обучение на меньшем количестве размерностей идёт сильно быстрее.
Инструмент на удивление хорошо подошел для определения тематик текстов (Topic Modelling). Мы смогли абстрагироваться от конкретных слов до уровня смыслов даже без привлечения учителя со списком категорий. Алгоритм назвали Латентно-семантический анализ (LSA), и его идея была в том, что частота появления слова в тексте зависит от его тематики: в научных статьях больше технических терминов, в новостях о политике — имён политиков. Да, мы могли бы просто взять все слова из статей и кластеризовать, как мы делали с ларьками выше, но тогда мы бы потеряли все полезные связи между словами, например, что батарейка и аккумулятор, означают одно и то же в разных документах.
Точность такой системы — полное дно, даже не пытайтесь.
Нужно как-то объединить слова и документы в один признак, чтобы не терять эти скрытые (латентные) связи. Отсюда и появилось название метода. Оказалось, что Сингулярное разложение (SVD) легко справляется с этой задачей, выявляя для нас полезные тематические кластеры из слов, которые встречаются вместе.

Другое мега-популярное применение метода уменьшения размерности нашли в рекомендательных системах и коллаборативной фильтрации. Оказалось, если абстрагировать ими оценки пользователей фильмам, получается неплохая система рекомендаций кино, музыки, игр и чего угодно вообще.
Полученная абстракция будет с трудом понимаема мозгом, но когда исследователи начали пристально рассматривать новые признаки, они обнаружили, что какие-то из них явно коррелируют с возрастом пользователя (дети чаще играли в Майнкрафт и смотрели мультфильмы), другие с определёнными жанрами кино, а третьи вообще с синдромом поиска глубокого смысла.
Машина, не знавшая ничего кроме оценок пользователей, смогла добраться до таких высоких материй, даже не понимая их. Достойно. Дальше можно проводить соцопросы и писать дипломные работы о том, почему бородатые мужики любят дегенеративные мультики.
На эту тему есть неплохая лекция Яндекса — Как работают рекомендательные системы
Поиск правил (ассоциация)

«Ищет закономерности в потоке заказов»
Сегодня используют для:
- Прогноз акций и распродаж
- Анализ товаров, покупаемых вместе
- Расстановка товаров на полках
- Анализ паттернов поведения на веб-сайтах
Сюда входят все методы анализа продуктовых корзин, стратегий маркетинга и других последовательностей.
Предположим, покупатель берёт в дальнем углу магазина пиво и идёт на кассу. Стоит ли ставить на его пути орешки? Часто ли люди берут их вместе? Орешки с пивом, наверное да, но какие ещё товары покупают вместе? Когда вы владелец сети гипермаркетов, ответ для вас не всегда очевиден, но одно тактическое улучшение в расстановке товаров может принести хорошую прибыль.
То же касается интернет-магазинов, где задача еще интереснее — за каким товаром покупатель вернётся в следующий раз?
По непонятным мне причинам, поиск правил — самая хреново продуманная категория среди всех методов обучения. Классические способы заключаются в тупом переборе пар всех купленных товаров с помощью деревьев или множеств. Сами алгоритмы работают наполовину — могут искать закономерности, но не умеют обобщать или воспроизводить их на новых примерах.
В реальности каждый крупный ритейлер пилит свой велосипед, и никаких особых прорывов в этой области я не встречал. Максимальный уровень технологий здесь — запилить систему рекомендаций, как в пункте выше. Хотя может я просто далёк от этой области, расскажите в комментах, кто шарит?

Часть 2. Обучение с подкреплением

«Брось робота в лабиринт и пусть ищет выход»
Сегодня используют для:
- Самоуправляемых автомобилей
- Роботов пылесосов
- Игр
- Автоматической торговли
- Управления ресурсами предприятий
Наконец мы дошли до вещей, которые, вроде, выглядят как настоящий искусственный интеллект. Многие авторы почему-то ставят обучение с подкреплением где-то между обучением с учителем и без, но я не понимаю чем они похожи. Названием?
Обучение с подкреплением используют там, где задачей стоит не анализ данных, а выживание в реальной среде.
Нейросеть играет в Марио
Средой может быть даже видеоигра. Роботы, играющие в Марио, были популярны еще лет пять назад. Средой может быть реальный мир. Как пример — автопилот Теслы, который учится не сбивать пешеходов, или роботы-пылесосы, главная задача которых — напугать вашего кота до усрачки с максимальной эффективностью.
Знания об окружающем мире такому роботу могут быть полезны, но чисто для справки. Не важно сколько данных он соберёт, у него всё равно не получится предусмотреть все ситуации. Потому его цель — минимизировать ошибки, а не рассчитать все ходы. Робот учится выживать в пространстве с максимальной выгодой: собранными монетками в Марио, временем поездки в Тесле или количеством убитых кожаных мешков хихихих.
Выживание в среде и есть идея обучения с подкреплением. Давайте бросим бедного робота в реальную жизнь, будем штрафовать его за ошибки и награждать за правильные поступки. На людях норм работает, почему бы на и роботах не попробовать.
Умные модели роботов-пылесосов и самоуправляемые автомобили обучаются именно так: им создают виртуальный город (часто на основе карт настоящих городов), населяют случайными пешеходами и отправляют учиться никого там не убивать. Когда робот начинает хорошо себя чувствовать в искусственном GTA, его выпускают тестировать на реальные улицы.
Запоминать сам город машине не нужно — такой подход называется Model-Free. Конечно, тут есть и классический Model-Based, но в нём нашей машине пришлось бы запоминать модель всей планеты, всех возможных ситуаций на всех перекрёстках мира. Такое просто не работает. В обучении с подкреплением машина не запоминает каждое движение, а пытается обобщить ситуации, чтобы выходить из них с максимальной выгодой.

Помните новость пару лет назад, когда машина обыграла человека в Го? Хотя незадолго до этого было доказано, что число комбинаций физически невозможно просчитать, ведь оно превышает количество атомов во вселенной. То есть если в шахматах машина реально просчитывала все будущие комбинации и побеждала, с Го так не прокатывало. Поэтому она просто выбирала наилучший выход из каждой ситуации и делала это достаточно точно, чтобы обыграть кожаного ублюдка.
Эта идея лежит в основе алгоритма Q-learning и его производных (SARSA и DQN). Буква Q в названии означает слово Quality, то есть робот учится поступать наиболее качественно в любой ситуации, а все ситуации он запоминает как простой марковский процесс.

Машина прогоняет миллионы симуляций в среде, запоминая все сложившиеся ситуации и выходы из них, которые принесли максимальное вознаграждение. Но как понять, когда у нас сложилась известная ситуация, а когда абсолютно новая? Вот самоуправляемый автомобиль стоит у перекрестка и загорается зелёный — значит можно ехать? А если справа мчит скорая помощь с мигалками?
Ответ — хрен знает, никак, магии не бывает, исследователи постоянно этим занимаются, изобретая свои костыли. Одни прописывают все ситуации руками, что позволяет им обрабатывать исключительные случаи типа проблемы вагонетки. Другие идут глубже и отдают эту работу нейросетям, пусть сами всё найдут. Так вместо Q-learning’а у нас появляется Deep Q-Network (DQN).
Reinforcement Learning для простого обывателя выглядит как настоящий интеллект. Потому что ух ты, машина сама принимает решения в реальных ситуациях! Он сейчас на хайпе, быстро прёт вперёд и активно пытается в нейросети, чтобы стать еще точнее (а не стукаться о ножку стула по двадцать раз).
Потому если вы любите наблюдать результаты своих трудов и хотите популярности — смело прыгайте в методы обучения с подкреплением (до чего ужасный русский термин, каждый раз передёргивает) и заводите канал на ютюбе! Даже я бы смотрел.
Помню, у меня в студенчестве были очень популярны генетические алгоритмы (по ссылке прикольная визуализация). Это когда мы бросаем кучу роботов в среду и заставляем их идти к цели, пока не сдохнут. Затем выбираем лучших, скрещиваем, добавляем мутации и бросаем еще раз. Через пару миллиардов лет должно получиться разумное существо. Теория эволюции в действии.
Так вот, генетические алгоритмы тоже относятся к обучению с подкреплением, и у них есть важнейшая особенность, подтвержденная многолетней практикой — они нахер никому не нужны.
Человечеству еще не удалось придумать задачу, где они были бы реально эффективнее других. Зато отлично заходят как студенческие эксперименты и позволяют кадрить научруков «достижениями» особо не заморачиваясь. На ютюбе тоже зайдёт.
Часть 3. Ансамбли

«Куча глупых деревьев учится исправлять ошибки друг друга»
Сегодня используют для:
- Всего, где подходят классические алгоритмы (но работают точнее)
- Поисковые системы (★)
- Компьютерное зрение
- Распознавание объектов
Теперь к настоящим взрослым методам. Ансамбли и нейросети — наши главные бойцы на пути к неминуемой сингулярности. Сегодня они дают самые точные результаты и используются всеми крупными компаниями в продакшене. Только о нейросетях трещат на каждом углу, а слова «бустинг» и «бэггинг», наверное, пугают только хипстеров с теккранча.
При всей их эффективности, идея до издевательства проста. Оказывается, если взять несколько не очень эффективных методов обучения и обучить исправлять ошибки друг друга, качество такой системы будет аж сильно выше, чем каждого из методов по отдельности.
Причём даже лучше, когда взятые алгоритмы максимально нестабильны и сильно плавают от входных данных. Поэтому чаще берут Регрессию и Деревья Решений, которым достаточно одной сильной аномалии в данных, чтобы поехала вся модель. А вот Байеса и K-NN не берут никогда — они хоть и тупые, но очень стабильные.
Ансамбль можно собрать как угодно, хоть случайно нарезать в тазик классификаторы и залить регрессией. За точность, правда, тогда никто не ручается. Потому есть три проверенных способа делать ансамбли.
Стекинг Обучаем несколько разных алгоритмов и передаём их результаты на вход последнему, который принимает итоговое решение. Типа как девочки сначала опрашивают всех своих подружек, чтобы принять решение встречаться с парнем или нет.

Ключевое слово — разных алгоритмов, ведь один и тот же алгоритм, обученный на одних и тех же данных не имеет смысла. Каких — ваше дело, разве что в качестве решающего алгоритма чаще берут регрессию.
Чисто из опыта — стекинг на практике применяется редко, потому что два других метода обычно точнее.
Беггинг Он же Bootstrap AGGregatING. Обучаем один алгоритм много раз на случайных выборках из исходных данных. В самом конце усредняем ответы.
Данные в случайных выборках могут повторяться. То есть из набора 1-2-3 мы можем делать выборки 2-2-3, 1-2-2, 3-1-2 и так пока не надоест. На них мы обучаем один и тот же алгоритм несколько раз, а в конце вычисляем ответ простым голосованием.

Самый популярный пример беггинга — алгоритм Random Forest, беггинг на деревьях, который и нарисован на картинке. Когда вы открываете камеру на телефоне и видите как она очертила лица людей в кадре желтыми прямоугольниками — скорее всего это их работа. Нейросеть будет слишком медлительна в реальном времени, а беггинг идеален, ведь он может считать свои деревья параллельно на всех шейдерах видеокарты.
Дикая способность параллелиться даёт беггингу преимущество даже над следующим методом, который работает точнее, но только в один поток. Хотя можно разбить на сегменты, запустить несколько… ах кого я учу, сами не маленькие.

Бустинг Обучаем алгоритмы последовательно, каждый следующий уделяет особое внимание тем случаям, на которых ошибся предыдущий.
Как в беггинге, мы делаем выборки из исходных данных, но теперь не совсем случайно. В каждую новую выборку мы берём часть тех данных, на которых предыдущий алгоритм отработал неправильно. То есть как бы доучиваем новый алгоритм на ошибках предыдущего.

Плюсы — неистовая, даже нелегальная в некоторых странах, точность классификации, которой позавидуют все бабушки у подъезда. Минусы уже названы — не параллелится. Хотя всё равно работает быстрее нейросетей, которые как гружёные камазы с песком по сравнению с шустрым бустингом.
Нужен реальный пример работы бустинга — откройте Яндекс и введите запрос. Слышите, как Матрикснет грохочет деревьями и ранжирует вам результаты? Вот это как раз оно, Яндекс сейчас весь на бустинге. Про Google не знаю.
Сегодня есть три популярных метода бустинга, отличия которых хорошо донесены в статье CatBoost vs. LightGBM vs. XGBoost
Часть 4. Нейросети и глубокое обучение

«У нас есть сеть из тысячи слоёв, десятки видеокарт, но мы всё еще не придумали где это может быть полезно. Пусть рисует котиков!»
Сегодня используют для:
- Вместо всех вышеперечисленных алгоритмов вообще
- Определение объектов на фото и видео
- Распознавание и синтез речи
- Обработка изображений, перенос стиля
- Машинный перевод
Если вам хоть раз не пытались объяснить нейросеть на примере якобы работы мозга, расскажите, как вам удалось спрятаться? Я буду избегать этих аналогий и объясню как нравится мне.
Любая нейросеть — это набор нейронов и связей между ними. Нейрон лучше всего представлять просто как функцию с кучей входов и одним выходом. Задача нейрона — взять числа со своих входов, выполнить над ними функцию и отдать результат на выход. Простой пример полезного нейрона: просуммировать все цифры со входов, и если их сумма больше N — выдать на выход единицу, иначе — ноль.
Связи — это каналы, через которые нейроны шлют друг другу циферки. У каждой связи есть свой вес — её единственный параметр, который можно условно представить как прочность связи. Когда через связь с весом 0.5 проходит число 10, оно превращается в 5. Сам нейрон не разбирается, что к нему пришло и суммирует всё подряд — вот веса и нужны, чтобы управлять на какие входы нейрон должен реагировать, а на какие нет.

Чтобы сеть не превратилась в анархию, нейроны решили связывать не как захочется, а по слоям. Внутри одного слоя нейроны никак не связаны, но соединены с нейронами следующего и предыдущего слоя. Данные в такой сети идут строго в одном направлении — от входов первого слоя к выходам последнего.
Если нафигачить достаточное количество слоёв и правильно расставить веса в такой сети, получается следующее — подав на вход, скажем, изображение написанной от руки цифры 4, чёрные пиксели активируют связанные с ними нейроны, те активируют следующие слои, и так далее и далее, пока в итоге не загорится самый выход, отвечающий за четвёрку. Результат достигнут.

В реальном программировании, естественно, никаких нейронов и связей не пишут, всё представляют матрицами и считают матричными произведениями, потому что нужна скорость. У меня есть два любимых видео, в которых весь описанный мной процесс наглядно объяснён на примере распознавания рукописных цифр. Посмотрите, если хотите разобраться.
Такая сеть, где несколько слоёв и между ними связаны все нейроны, называется перцептроном (MLP) и считается самой простой архитектурой для новичков. В боевых задачах лично я никогда её не встречал.
Когда мы построили сеть, наша задача правильно расставить веса, чтобы нейроны реагировали на нужные сигналы. Тут нужно вспомнить, что у нас же есть данные — примеры «входов» и правильных «выходов». Будем показывать нейросети рисунок той же цифры 4 и говорить «подстрой свои веса так, чтобы на твоём выходе при таком входе всегда загоралась четвёрка».
Сначала все веса просто расставлены случайно, мы показываем сети цифру, она выдаёт какой-то случайный ответ (весов-то нет), а мы сравниваем, насколько результат отличается от нужного нам. Затем идём по сети в обратном направлении, от выходов ко входам, и говорим каждому нейрону — так, ты вот тут зачем-то активировался, из-за тебя всё пошло не так, давай ты будешь чуть меньше реагировать на вот эту связь и чуть больше на вон ту, ок?
Через тысяч сто таких циклов «прогнали-проверили-наказали» есть надежда, что веса в сети откорректируются так, как мы хотели. Научно этот подход называется Backpropagation или «Метод обратного распространения ошибки». Забавно то, что чтобы открыть этот метод понадобилось двадцать лет. До него нейросети обучали как могли.
Второй мой любимый видос более подробно объясняет весь процесс, но всё так же просто, на пальцах.
Хорошо обученная нейросеть могла притворяться любым алгоритмом из этой статьи, а зачастую даже работать точнее. Такая универсальность сделала их дико популярными. Наконец-то у нас есть архитектура человеческого мозга, говорили они, нужно просто собрать много слоёв и обучить их на любых данных, надеялись они. Потом началась первая Зима ИИ, потом оттепель, потом вторая волна разочарования.
Оказалось, что на обучение сети с большим количеством слоёв требовались невозможные по тем временам мощности. Сейчас любое игровое ведро с жифорсами превышает мощность тогдашнего датацентра. Тогда даже надежды на это не было, и в нейросетях все сильно разочаровались.
Пока лет десять назад не бомбанул диплёрнинг.
На английской википедии есть страничка Timeline of machine learning, где хорошо видны всплески радости и волны отчаяния.
В 2012 году свёрточная нейросеть порвала всех в конкурсе ImageNet, из-за чего в мире внезапно вспомнили о методах глубокого обучения, описанных еще в 90-х годах. Теперь-то у нас есть видеокарты!
Отличие глубокого обучения от классических нейросетей было в новых методах обучения, которые справлялись с большими размерами сетей. Однако сегодня лишь теоретики разделяют, какое обучение можно считать глубоким, а какое не очень. Мы же, как практики, используем популярные «глубокие» библиотеки типа Keras, TensorFlow и PyTorch даже когда нам надо собрать мини-сетку на пять слоёв. Просто потому что они удобнее всего того, что было раньше. Мы называем это просто нейросетями.
Расскажу о двух главных на сегодняшний момент.
Свёрточные Нейросети (CNN)
Свёрточные сети сейчас на пике популярности. Они используются для поиска объектов на фото и видео, распознавания лиц, переноса стиля, генерации и дорисовки изображений, создания эффектов типа слоу-мо и улучшения качества фотографий. Сегодня CNN применяют везде, где есть картинки или видео. Даже в вашем айфоне несколько таких сетей смотрят на ваши голые фотографии, чтобы распознать объекты на них. Если там, конечно, есть что распознавать хехехе.

Картинка выше — результат работы библиотеки Detectron, которую Facebook недавно заопенсорсил
Проблема с изображениями всегда была в том, что непонятно, как выделять на них признаки. Текст можно разбить по предложениям, взять свойства слов из словарей. Картинки же приходилось размечать руками, объясняя машине, где у котика на фотографии ушки, а где хвост. Такой подход даже назвали «handcrafting признаков» и раньше все так и делали.

Проблем у ручного крафтинга много.
Во-первых, если котик на фотографии прижал ушки или отвернулся — всё, нейросеть ничего не увидит.
Во-вторых, попробуйте сами сейчас назвать хотя бы десять характерных признаков, отличающих котиков от других животных. Я вот не смог. Однако когда ночью мимо меня пробегает чёрное пятно, даже краем глаза я могу сказать котик это или крыса. Потому что человек не смотрит только на форму ушей и количество лап — он оценивает объект по куче разных признаков, о которых сам даже не задумывается. А значит, не понимает и не может объяснить машине.
Получается, машине надо самой учиться искать эти признаки, составляя из каких-то базовых линий. Будем делать так: для начала разделим изображение на блоки 8×8 пикселей и выберем какая линия доминирует в каждом — горизонтальная [-], вертикальная [|] или одна из диагональных [/]. Могут и две, и три, так тоже бывает, мы не всегда точно уверены.
На выходе мы получим несколько массивов палочек, которые по сути являются простейшими признаками наличия очертаний объектов на картинке. По сути это тоже картинки, просто из палочек. Значит мы можем вновь выбрать блок 8×8 и посмотреть уже, как эти палочки сочетаются друг с другом. А потом еще и еще.
Такая операция называется свёрткой, откуда и пошло название метода. Свёртку можно представить как слой нейросети, ведь нейрон — абсолютно любая функция.

Когда мы прогоняем через нашу нейросеть кучу фотографий котов, она автоматически расставляет большие веса тем сочетаниям из палочек, которые увидела чаще всего. Причём неважно, это прямая линия спины или сложный геометрический объект типа мордочки — что-то обязательно будет ярко активироваться.
На выходе же мы поставим простой перцептрон, который будет смотреть какие сочетания активировались и говорить кому они больше характерны — кошке или собаке.

Красота идеи в том, что у нас получилась нейросеть, которая сама находит характерные признаки объектов. Нам больше не надо отбирать их руками. Мы можем сколько угодно кормить её изображениями любых объектов, просто нагуглив миллион картинок с ними — сеть сама составит карты признаков из палочек и научится определять что угодно.
По этому поводу у меня даже есть несмешная шутка:
Дай нейросети рыбу — она сможет определять рыбу до конца жизни. Дай нейросети удочку — она сможет определять и удочку до конца жизни…
Рекуррентные Нейросети (RNN)
Вторая по популярности архитектура на сегодняшний день. Благодаря рекуррентным сетям у нас есть такие полезные вещи, как машинный перевод текстов и компьютерный синтез речи. На них решают все задачи, связанные с последовательностями — голосовые, текстовые или музыкальные.
Помните олдскульные голосовые синтезаторы типа Microsoft Sam из Windows XP, который смешно произносил слова по буквам, пытаясь как-то склеить их между собой? А теперь посмотрите на Amazon Alexa или Алису от Яндекса — они сегодня не просто произносят слова без ошибок, они даже расставляют акценты в предложении!
Нейросеть учится разговаривать
Потому что современные голосовые помощники обучают говорить не буквами, а фразами. Но сразу заставить нейросеть целиком выдавать фразы не выйдет, ведь тогда ей надо будет запомнить все фразы в языке и её размер будет исполинским. Тут на помощь приходит то, что текст, речь или музыка — это последовательности. Каждое слово или звук — как бы самостоятельная единица, но которая зависит от предыдущих. Когда эта связь теряется — получатся дабстеп.
Достаточно легко обучить сеть произносить отдельные слова или буквы. Берём кучу размеченных на слова аудиофайлов и обучаем по входному слову выдавать нам последовательность сигналов, похожих на его произношение. Сравниваем с оригиналом от диктора и пытаемся максимально приблизиться к идеалу. Для такого подойдёт даже перцептрон.
Вот только с последовательностью опять беда, ведь перцептрон не запоминает что он генерировал ранее. Для него каждый запуск как в первый раз. Появилась идея добавить к каждому нейрону память. Так были придуманы рекуррентные сети, в которых каждый нейрон запоминал все свои предыдущие ответы и при следующем запуске использовал их как дополнительный вход. То есть нейрон мог сказать самому себе в будущем — эй, чувак, следующий звук должен звучать повыше, у нас тут гласная была (очень упрощенный пример).

Была лишь одна проблема — когда каждый нейрон запоминал все прошлые результаты, в сети образовалось такое дикое количество входов, что обучить такое количество связей становилось нереально.
Когда нейросеть не умеет забывать — её нельзя обучить (у людей та же фигня).
Сначала проблему решили в лоб — обрубили каждому нейрону память. Но потом придумали в качестве этой «памяти» использовать специальные ячейки, похожие на память компьютера или регистры процессора. Каждая ячейка позволяла записать в себя циферку, прочитать или сбросить — их назвали ячейки долгой и краткосрочной памяти (LSTM).
Когда нейрону было нужно поставить себе напоминалку на будущее — он писал это в ячейку, когда наоборот вся история становилась ненужной (предложение, например, закончилось) — ячейки сбрасывались, оставляя только «долгосрочные» связи, как в классическом перцептроне. Другими словами, сеть обучалась не только устанавливать текущие связи, но и ставить напоминалки.
Просто, но работает!
CNN + RNN = фейковый Обама
Озвученные тексты для обучения начали брать откуда угодно. Даже базфид смог выгрузить видеозаписи выступлений Обамы и весьма неплохо научить нейросеть разговаривать его голосом. На этом примере видно, что имитировать голос — достаточно простая задача для сегодняшних машин. С видео посложнее, но это пока.
Про архитектуры нейросетей можно говорить бесконечно. Любознательных отправляю смотреть схему и читать статью Neural Network Zoo, где собраны все типы нейронных сетей. Есть и русская версия.

Заключение: когда на войну с машинами?
На вопрос «когда машины станут умнее нас и всех поработят?» я всегда отвечаю, что он заранее неправильный. В нём слишком много скрытых условий, который примаются как как данность.
Вот мы говорим «станут умнее нас». Значит мы подразумеваем, что существует некая единая шкала интеллекта, наверху которой находится человек, собаки пониже, а глупые голуби тусят в самом низу. Получается человек должен превосходить нижестоящих животных во всём, так? А в жизни не так. Средняя белка может помнить тысячу тайников в орешками, а я не могу вспомнить где ключи. Получается интеллект — это набор разных навыков, а не единая измеримая величина? Или просто запоминание орешков в него не входит? А убивание человеков входит?
Ну и самый интересный для меня вопрос — почему мы заранее считаем, что возможности человеческого мозга ограничены? В интернетах обожают рисовать графики, на которых технологический прогресс обозначен экспонентой, а возможности кожаных мешков константой. Но так ли это?
Вот давайте, прямо сейчас в уме умножьте 1680 на 950. Да, знаю, вы даже пытаться не станете. Но дай вам калькулятор, это займёт две секунды. Значит ли это, что вы только что расширили возможности своего мозга с помощью калькулятора? Можно ли продолжать их расширять другими машинами? Я вот использую заметки на телефоне — значит ли это, что я расширяю свою память с помощью машины?
Получается, мы уже успешно расширяем способности нашего мозга с помощью машин. Или нет?
Подумайте. У меня всё.

Читайте также
Я в своей жизни ещё ни разу не встречал проекта, где бы всё было сделано по правилам проектирования архитектуры, с…
На Harvard Business Review вышла забавная статья Is “Murder by Machine Learning” the New “Death by PowerPoint”? Для тех, кто не в…
Совсем недавно британская компания MicroBlink выпустила приложение PhotoMath, способное распознавать текст математических примеров из учебника или с экрана (работает чуть…
https://tproger.ru/translations/top-machine-learning-algorithms/